...
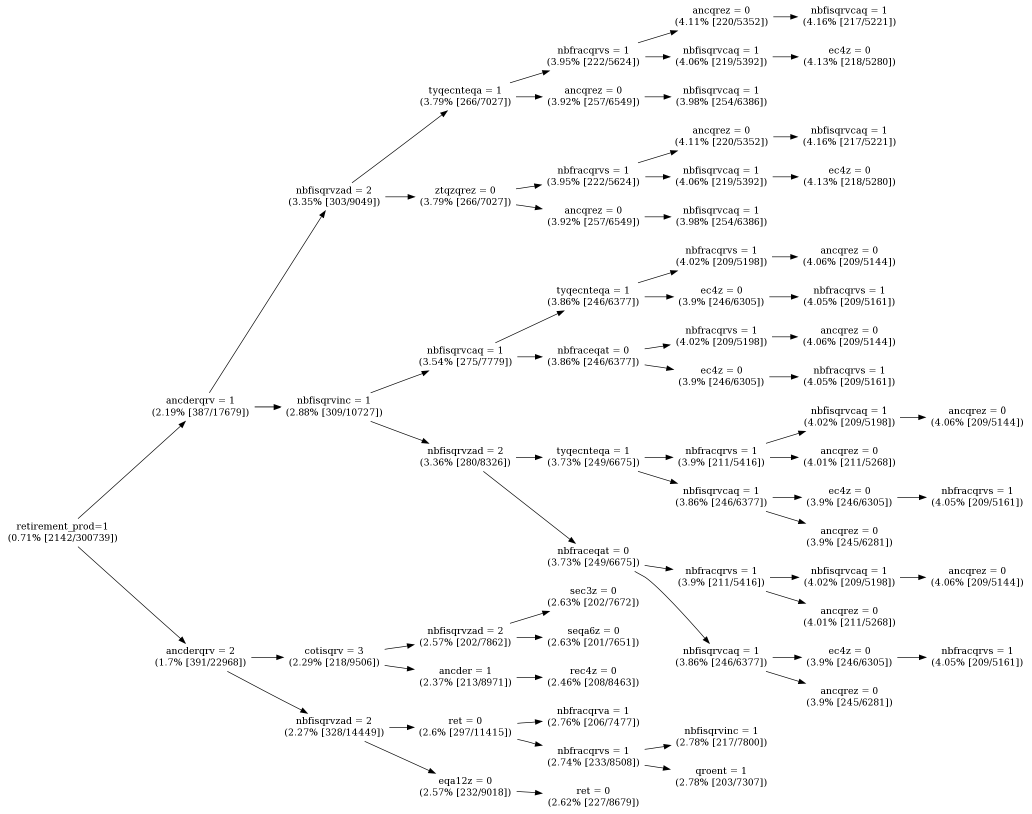
Here is the same output depicted in graphical form using the excellent Graphvizgraph visualization software from AT&T Research.
HotSpot is fast. E.g. a data set of 300,000 records with 45 discrete-valued fields can be processed in ~30 seconds (~10 seconds and consumes ~240Mb of memory on a 2.16GHz core 2 duo processor using Java 1.6 (data and model held in main memory). Adjustment of HotSpot's parameters (especially the "branching factor" parameter) does impact on runtime. Presence of numeric fields has an impact on runtime as well (due to the need for sorting and the evaluation of many potential split points).
Here is the output of HotSpot on a real-world insurance data set. There are 300,739 records and 45 discrete-valued fields. The target of interest is those customers who have purchased a lucrative retirement investment product. The field names have been changed for confidentiality reasons but relate to demographic and purchasing information (policies purchased, policies cancelled, taxes etc.). HotSpot finds segments where customers who purchased the product are close to six times more prevalent (lift factor) than in the whole population.