HotSpot Segmentation-Profiling
NOTE: HotSpot is available in Weka 3.5.8 and higher. From Weka 3.7.2 it has moved to a package called "hotSpot", which can be installed via the package manager in Weka 3.7.2. Package information can be browsed online: http://weka.sourceforge.net/packageMetaData/hotSpot/index.html
HotSpot learns a set of rules (displayed in a tree-like structure) that maximize/minimize a target variable/value of interest. With a nominal target, one might want to look for segments of the data where there is a high probability of a minority value occurring (given the constraint of a minimum support). For a numeric target, one might be interested in finding segments where this is higher on average than in the whole data set. For example, in a health insurance scenario, find which health insurance groups are at the highest risk (have the highest claim ratio), or, which groups have the highest average insurance pay-out.
Here is an example of the output of HotSpot on the small Canadian labor negotiations data set (available from the UCI machine learning archive). HotSpot has focussed on those contracts that were rejected (bad), which is the minority class.
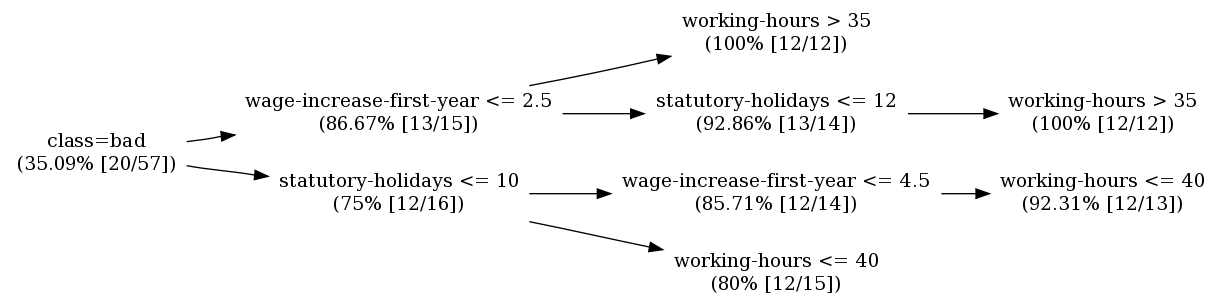
Hot Spot ======== Total population: 57 instances Target attribute: class Target value: bad [value count in total population: 20 instances (35.09%)] Minimum value count for segments: 12 instances (21.05% of total population) Maximum branching factor: 2 Minimum improvement in target: 1% class=bad (35.09% [20/57]) wage-increase-first-year <= 2.5 (86.67% [13/15]) | working-hours > 35 (100% [12/12]) | statutory-holidays <= 12 (92.86% [13/14]) | | working-hours > 35 (100% [12/12]) statutory-holidays <= 10 (75% [12/16]) | wage-increase-first-year <= 4.5 (85.71% [12/14]) | | working-hours <= 40 (92.31% [12/13]) | working-hours <= 40 (80% [12/15])
Here is the same output depicted in graphical form using the excellent Graphvizgraph visualization software from AT&T Research.
HotSpot is fast. E.g. a data set of 300,000 records with 45 discrete-valued fields can be processed in ~10 seconds and consumes ~240Mb of memory on a 2.16GHz core 2 duo processor using Java 1.6 (data and model held in main memory). Adjustment of HotSpot's parameters (especially the "branching factor" parameter) does impact on runtime. Presence of numeric fields has an impact on runtime as well (due to the need for sorting and the evaluation of many potential split points).
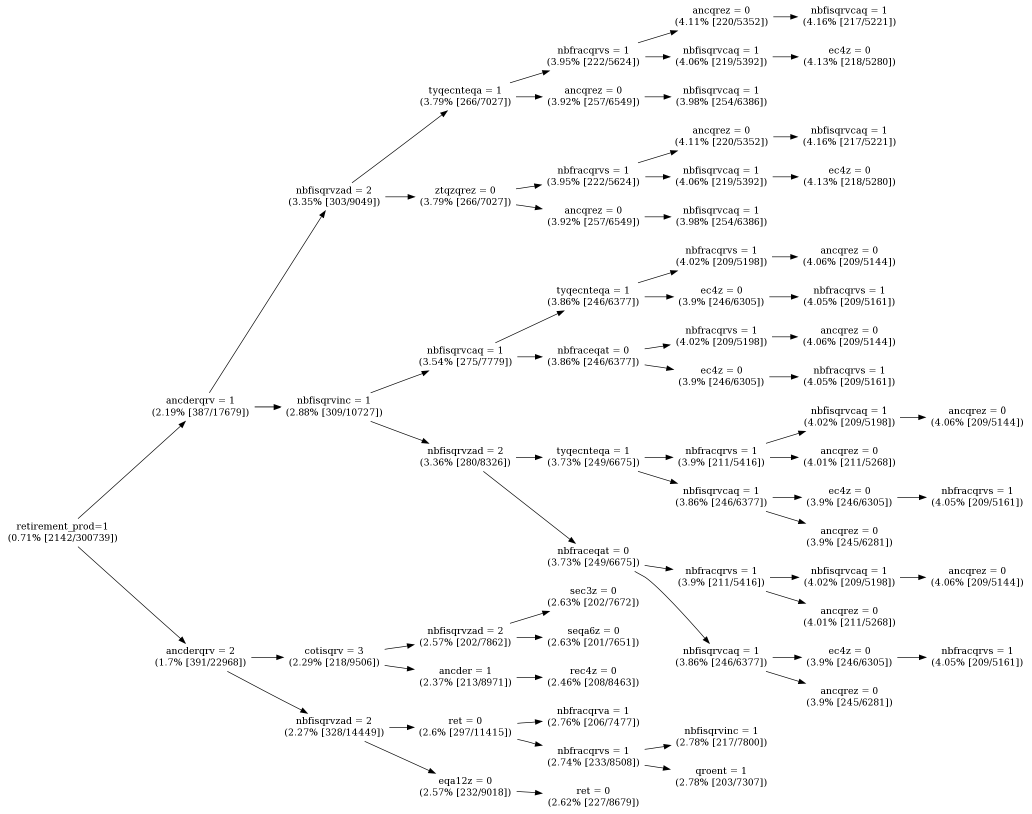
Here is the output of HotSpot on a real-world insurance data set. There are 300,739 records and 45 discrete-valued fields. The target of interest is those customers who have purchased a lucrative retirement investment product. The field names have been changed for confidentiality reasons but relate to demographic and purchasing information (policies purchased, policies cancelled, taxes etc.). HotSpot finds segments where customers who purchased the product are close to six times more prevalent (lift factor) than in the whole population.