Avro Input (Deprecated)
![]() PLEASE NOTE: This documentation applies to an earlier version. For the most recent documentation, visit the Pentaho Enterprise Edition documentation site.
PLEASE NOTE: This documentation applies to an earlier version. For the most recent documentation, visit the Pentaho Enterprise Edition documentation site.
Description
The Avro Input step decodes binary or JSON Avro data and extracts fields from the structure it defines, either from flat files or incoming fields.
Sample data
The examples use Avro data that has been encoded according to the following schema
{
"type": "record",
"name": "Person",
"fields": [
{"name": "name", "type": "string"},
{"name": "age", "type": "int"},
{"name": "emails", "type": {"type": "array", "items": "string"}}
]
}
where the example data in question looks like (in Json encoding)
{"name":"bob","age":20,"emails":["here is an email","and another one"]}
{"name":"fred","age":25,"emails":["hi there bob","good to see you!","Yarghhh!"]}
{"name":"zaphod","age":1,"emails":["I'm from beetlejuice","yeah yeah yeah"]}
Options
Configuration settings
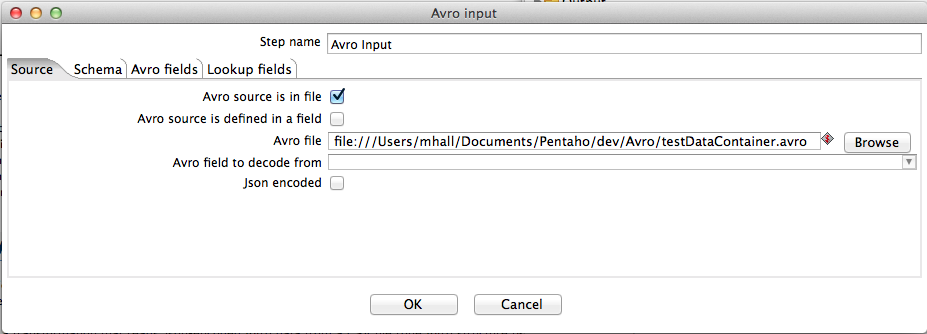
Option | Definition |
|---|---|
Avro source is in file | Indicates the source data comes from a file. |
Avro source is defined in a field | Indicates the source data comes from a field, and you can select an incoming field to decode from the Avro field to decode from drop-down box. In this mode of operation, a schema file must be specified in the Schema file field. |
Avro file | Specifies the file to decode. |
Avro field to decode from | Specifies the incoming field containing Avro data to decode. |
JSON encoded | Indicates the Avro data has been encoded in JSON. |
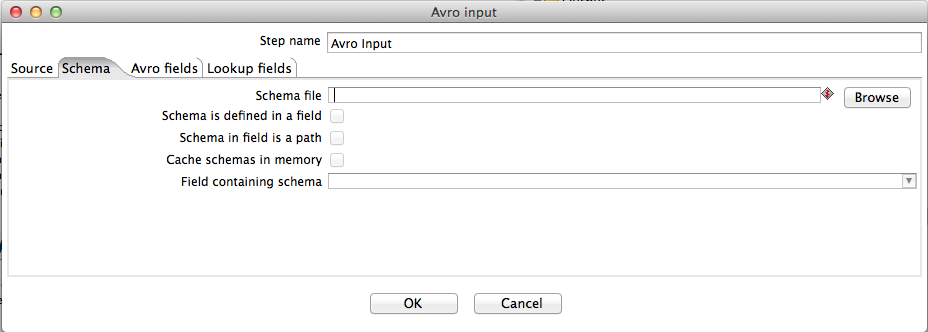
Option | Definition |
|---|---|
Schema file | Indicates an Avro schema file. |
Schema is defined in a field | Indicates the schema specified to use for decoding an incoming Avro object is found within a field. When checked, this option enables the Schema in field is a path and Cache schemas options. This also changes the Schema file label to Default schema file, which the user can specify if an incoming schema is missing. |
Schema in field is a path | Indicates that the incoming schema specifies a path to a schema file. If left unchecked, the step assumes the incoming schema is the actual schema definition in JSON format. |
Cache schemas in memory | Enables the step to retain all schemas seen in memory and uses this before loading or parsing an incoming schema. |
Field containing schema | Indicates which field contains the Avro schema. |
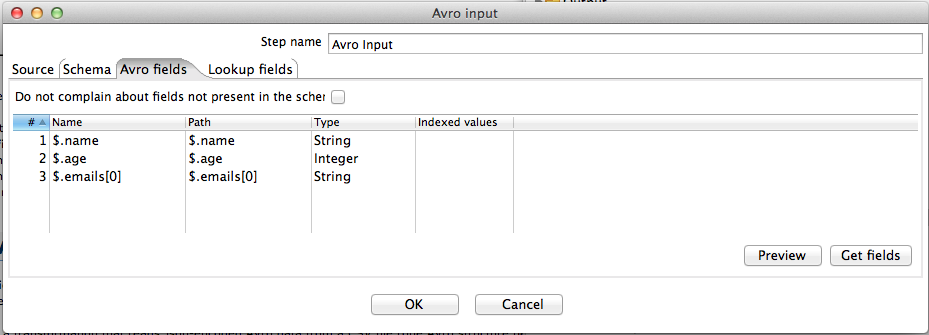
Option | Definition |
|---|---|
Do not complain about fields not present in the schema | Disables issuing an exception when specified paths or fields are not present in the active Avro schema. Instead a null value is returned. OR Instead the system returns a null value. |
Preview | Displays a review of the fields or data from the designated source file. |
Get fields | Populates the fields available from the designated source file or schema and gives each extracted field a name that reflects the path used to extract it. |
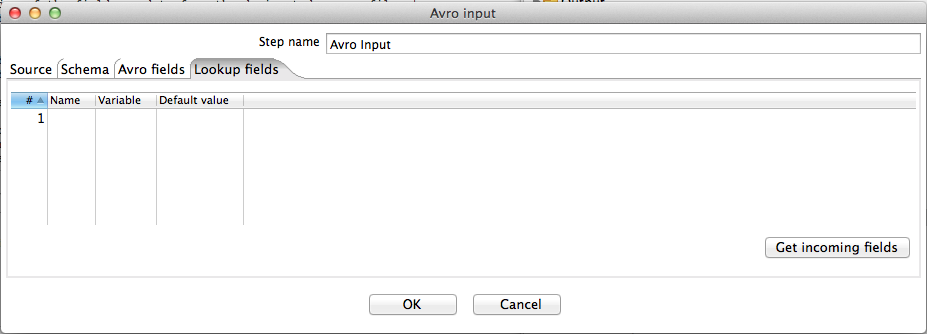
Option | Definition |
|---|---|
Get incoming fields | Populates the Name column of the table with the names of incoming Kettle fields. The Variable column of the table allows you to assign the values of these incoming fields to variable. A default value (to use in case the incoming field value is null) can be supplied in the Default value column. These variables can then be used anywhere in the Avro paths defined in the Avro fields tab. |
Example
Decoding Avro data from files
The screenshots above show the Avro input step after it has been configured to read an Avro container file encoded using the above schema.
The Source is in file checkbox has been selected to indicate that the source data is coming from a file. The Avro file text box specifies the file to decode. Because this file is a container file, no separate schema file has been specified (because the container file encapsulates the schema used to encode the data). However, if a schema file is provided in this case, via the Schema file text box, then schema resolution is attempted.
On the Avro Fields tab, a list of leaf primitives is shown, along with the path (in "dot" notation) that will be used to extract them from the hierarchical Avro structure. This shows all leaf primitives and has been populated by pressing the Get fields button. The user may add or remove rows (fields) from this table. By default, pressing the Get fields button gives each extracted field a name that is the same as the path used to extract it. The user may change these names to more meaningful ones. Any arrays in the Avro structure are shown in the path(s) with default index of 0 for access. Again the user may change this or add new fields that access other elements of the array. Similarly, if the Avro structure contains a map, this is shown by default in array notation with the default key value of "key" (e.g. $.my.path.with.a.map[key]). In this case, the default "key" key should be changed to something meaningful before data is extracted.
Decoding Avro data from a field
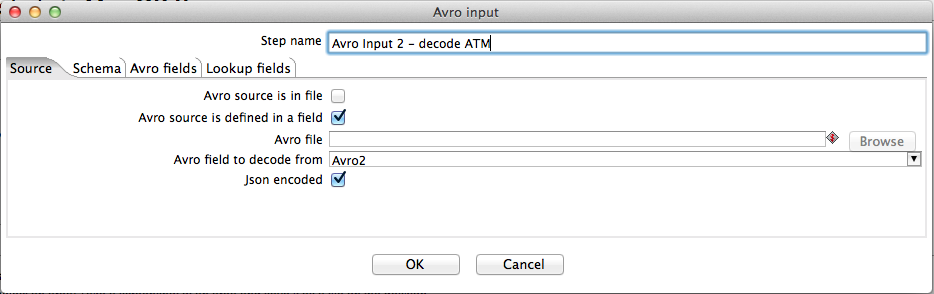
If the Source is defined in a field checkbox has been selected then the Avro file text box is disabled and the user can select an incoming field to decode from the Avro field to decode from drop-down box. In this mode of operation a schema file must be specified in the Schema file text box.
The following screenshots show a transformation that reads Json-encoded Avro data from a CSV file (one Avro structure per row) and passes it to the Avro input step for decoding.
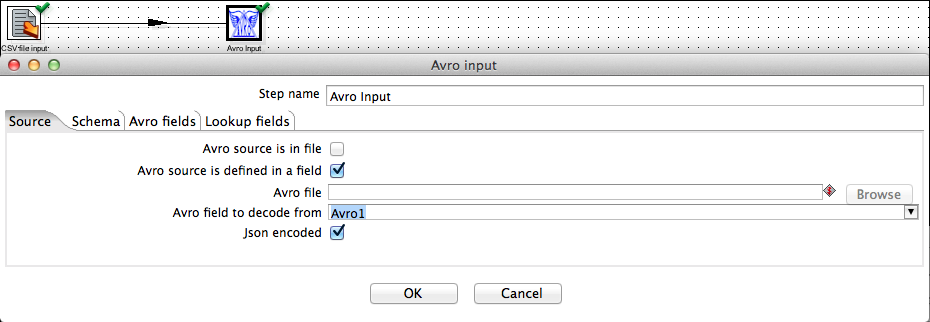

Note that for clarity, in this example and the ones that follow, we are using Json encoded Avro data. Binary encoded Avro data - sourced from binary files or database tables - can be decoded in the same fashion.
Expanding maps and arrays
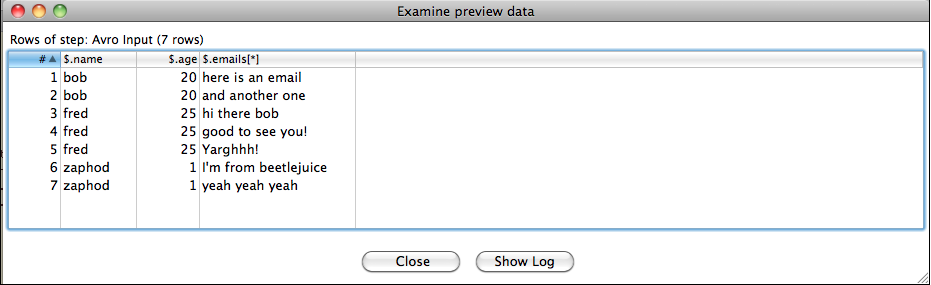
The Avro input step has the ability to expand a single map or array that occurs in the data structure being decoded. This means that a single incoming Avro structure gets converted into multiple outgoing rows of data - i.e. one row for each element in the array/map in question. In our example schema there is an array of emails where, for the sake of simplicity, each "email" is just a single string. All emails for a given person can be extracted by specifying "*" as the array index. For particular incoming Person object this results in one outgoing row for each email in the array.
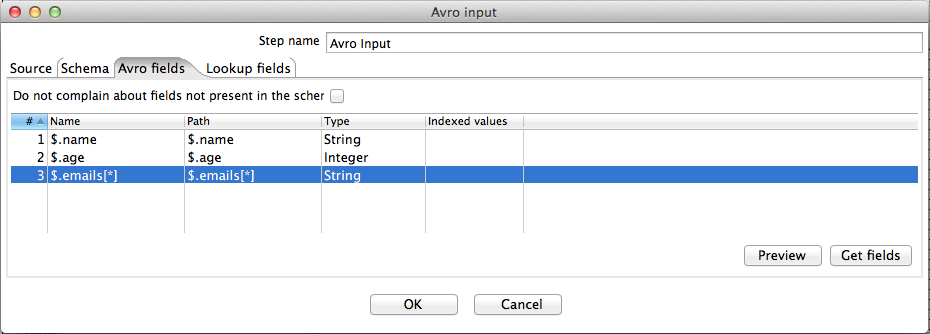
The Preview:
IMPORTANT: only a single map or array in the structure can be expanded in this fashion.
If the array in our example contained records (rather than just strings) we could define multiple paths such as
$.emails[*].sender $.emails[*].recipient ...
However, defining paths that expand more than one different map/array will result in an error. For example, if our example also contained an array of nicknames the following would result in an error
$.emails[*].sender $.emails[*].recipient $.nicknames[*]
Lookup fields
If there is more than one incoming field that contains Avro data then several Avro input steps can be chained in sequence in order to decode them. Furthermore, decoded field values from one Avro structure can be used as lookups into another at decoding time.
For this example we augment our Person schema with an array of ATM machine identifiers that could, for example, indicate the ATM machines that they have accessed on a given day.
{
"type": "record",
"name": "Person",
"fields": [
{"name": "name", "type": "string"},
{"name": "age", "type": "int"},
{"name": "emails", "type": {"type": "array", "items": "string"}},
{"name": "ATMS", "type": {"type": "array", "items": "string"}}
]
}
And now our example Person data looks like
{"name":"bob","age":20,"emails":["here is an email","and another one"],"ATMS":["atm1","atm20", "atm4"]}
{"name":"fred","age":25,"emails":["hi there bob","good to see you!","Yarghhh!"],"ATMS":["atm2","atm6"]}
{"name":"zaphod","age":1,"emails":["I'm from beetlejuice","yeah yeah yeah"],"ATMS":["atm10"]}
Furthermore, say we had information on a fixed set of ATM machines defined by the following schema
{
"type": "map",
"values":{
"type": "record",
"name":"ATM",
"fields": [
{"name": "serial_no", "type": "string"},
{"name": "location", "type": "string"}
]
}
}
And ATM data like so
{
"atm1": {"serial_no": "zxy555", "location": "Uptown"},
"atm2": {"serial_no": "vvv242", "location": "Downtown"},
"atm4": {"serial_no": "zzz111", "location": "Central"},
"atm6": {"serial_no": "piu786", "location": "Eastside"},
"atm10": {"serial_no": "hbc999", "location": "Westside"},
"atm20": {"serial_no": "mmm456", "location": "Lunar city"}
}
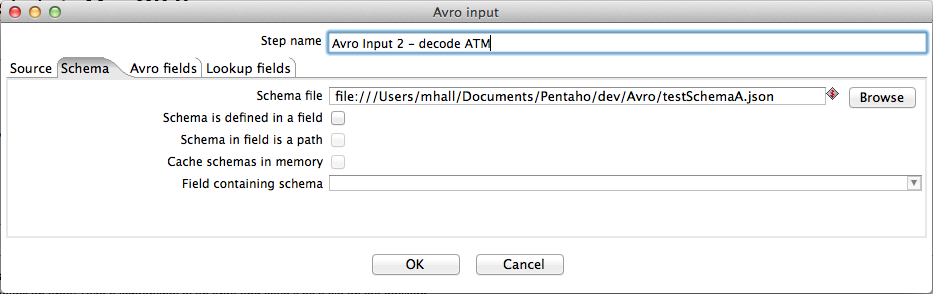
Assume that this fixed set of ATMs is carried in a second incoming Avro field - "Avro2".
The following transformation decodes both Avro fields and performs a "join" operation between the two
![]()
The following screenshots show the configuration of the first Avro input step. We use this to decode the Person data and to expand the array of ATMs that each person has used.
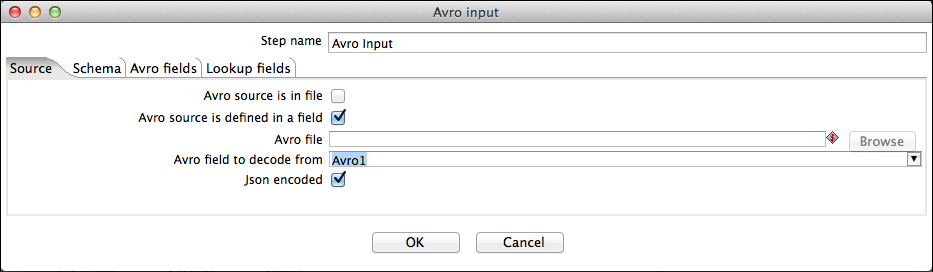
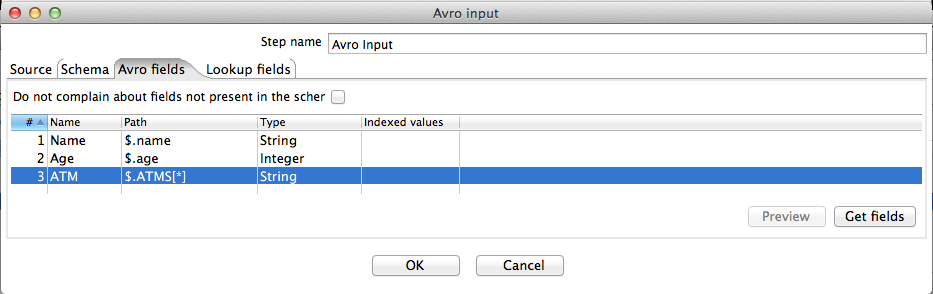
The screenshots below show the configuration of the second Avro input step. We use this to decode the ATM data and perform a lookup by using the value of the incoming ATM ID (field "ATM") as a key into the ATM map to obtain the corresponding serial number and location fields.
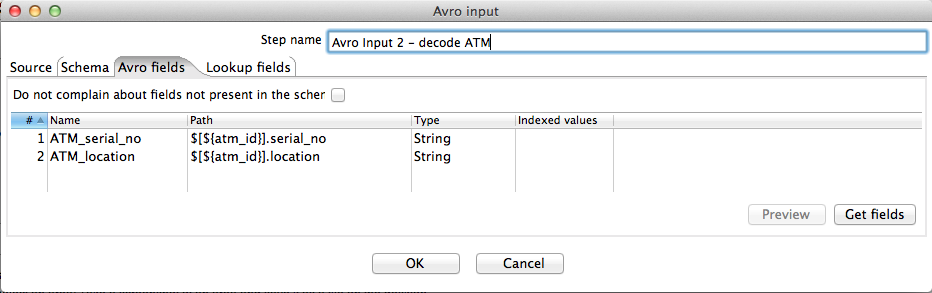
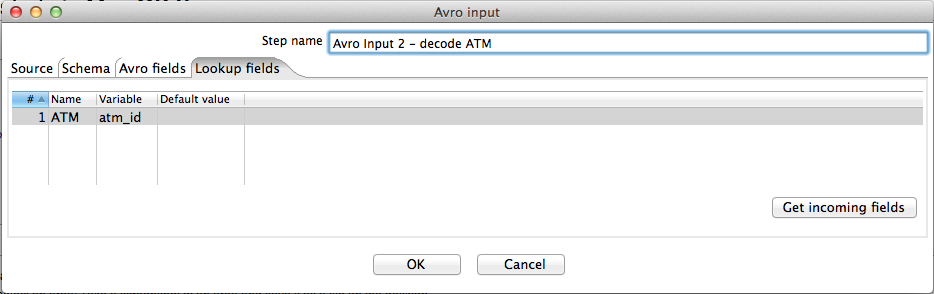
The "join" operation is facilitated by defining a lookup variable in the Lookup fields tab of the second Avro input step
Previewing the output of the second Avro input step shows 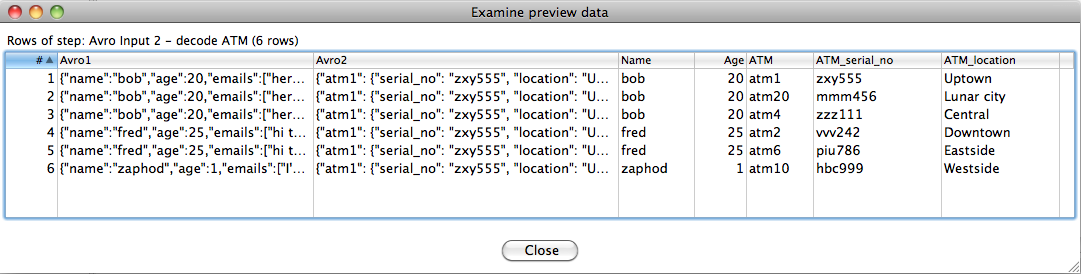
Metadata Injection Support (7.x and later)
All fields of this step support metadata injection. You can use this step with ETL Metadata Injection to pass metadata to your transformation at runtime.