MongoDB Output
![]() PLEASE NOTE: This documentation applies to an earlier version. For the most recent documentation, visit the Pentaho Enterprise Edition documentation site.
PLEASE NOTE: This documentation applies to an earlier version. For the most recent documentation, visit the Pentaho Enterprise Edition documentation site.
Description
MongoDb output is an output step that allows data to be written to a MongoDB collection. This step and its documentation are currently under development.
Options
This section describes the basic usage of the step - in particular, how to connect to MongoDB and configure the available options for writing data.
Configure Connection Tab
The screenshot below shows the GUI dialog for the MongoDb output step. 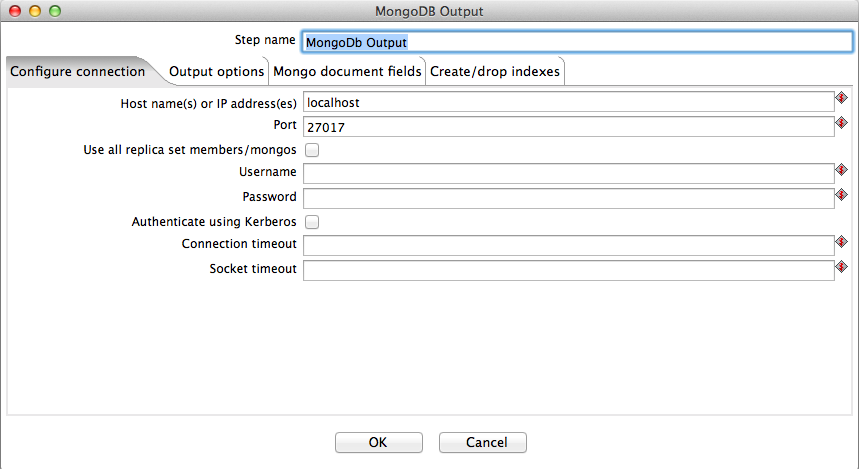
The Host name or IP address field and Port field hold basic connection details. Below this, the Username and Password field can be used to provide authentication details if the target collection requires it. The Database and Collection fields are used to set the database to use and the collection to write to within the database. If a valid hostname and port have already been set, then the Get DBs button and Get collections button can be used to retrieve the names of existing databases and collections within a selected database respectively.
Multiple hosts can be used by specifying the "Use all replicate set members/mongos", or via providing a comma-separated list of hostnames, and is supported in PDI 4.4.2 and later.
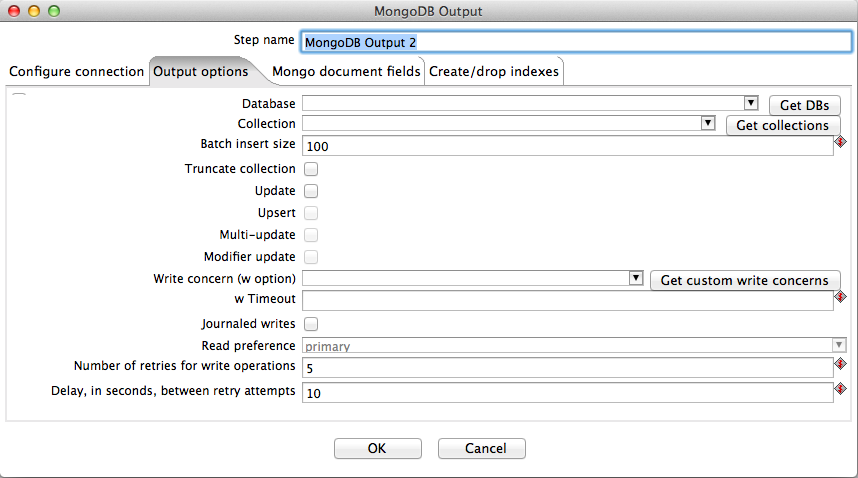
Output Options Tab
The MongoDb output step provides a number of options that control what and how data is written to the target Mongo document collection. By default, data is inserted into the target collection. If the specified collection doesn't exist, it will be created before data is inserted. Selecting the Truncate option will delete any existing data in the target collection before inserting begins. Unless unique indexes are being used (see section on indexing below) then Mongo DB will allow duplicate records to be inserted. Mongo DB allows for fast bulk insert operations - the batch size can be configured using the Batch insert size field. If no value is supplied here, then the default size of 100 rows is used.
Selecting the Upsert option changes the write mode from insert to upsert (i.e. update if a match is found, otherwise insert a new record). Information on defining how records are matched can be found in the next section. Standard upsert replaces a matched record with an entire new record based on all the incoming fields specified in the Mongo document fields tab. Modifier update enables modifier ($ operators) to be used to mutate individual fields within matching documents. This type of update is fast and involves minimal network traffic; it also has the ability to update all matching documents, rather than just the first, if the Multi-update option is enabled.
Mongo Document Fields Tab
The Mongo document fields tab allows the user to define how field values that are coming into the step get written to a mongo document. A document structure with an arbitrary hierarchy can be defined here.
Suppose we have the following input data
first, last, address, age Bob, Jones ,"13 Bob Street", 34 Fred, Flintstone, "10 Rock Street",50 Zaphod, Beeblebrox, "Beetlejuice 1", 356 Noddy,Puppet,"Noddy Land",5
and we wanted the following document structure in MongoDB
{
"top1" : {
"first" : "<string val>"
},
"array" : [ { "last" : "<string val>" , "address" : "<string val>"}],
"age" : "<integer val>"
}
then the following document field definitions would do the trick.
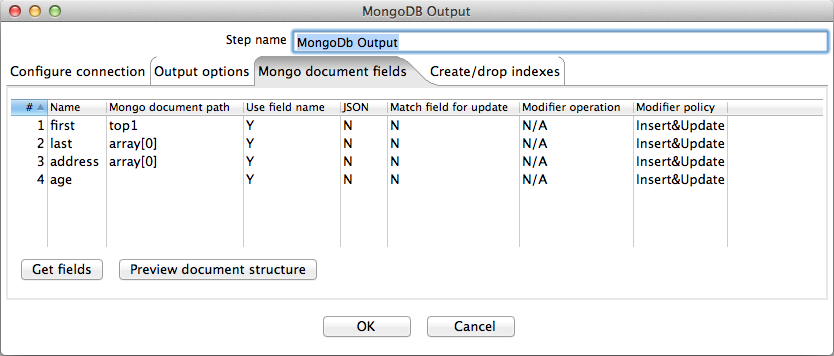
The Get fields button populates the left-hand column of the table with the names of the incoming fields. The Mongo document path column is where the hierarchical path to each field is defined for the document. These paths use the dot notation for separating objects. The Use field name column allows the user to specify whether the incoming field name is to be used as the final entry in the path. When this is set to "Y" for a field, a preceding "." is assumed. For example "array[0].last" is equivalent to the second row of the table above when Use field name is set to "N". If we'd wanted the incoming address field to be stored directly into the second element of the array (rather than being a member of a record at the first element of the array, as shown in the example) then we'd set Use field name to "N" and set the Mongo document path to "array[1]".
The Match field for upsert column allows the user to specify which of the fields should be used for matching when performing an upsert operation. The first document in the collection that matches all fields tagged as "Y" in this column is replaced with the new document constructed with incoming values for all the field paths tagged with "N". Therefore, any paths used to match need to be duplicated with tag "N" in order to be part of the document used to replace a matching one. If no matching document is found, then a new document is inserted into the collection.
Upsert only replaces the first matching document. Modifier upserts can be used to replace certain field values in multiple documents.
The Preview document structure button pops up a dialog that shows the structure that will be written to MongoDB in Json format.
Modifier Updates
The MongoDb output step supports modifier updates. These are in place modifications of existing document fields and are much faster than replacing a document with a new one. It is also possible to update more than one matching document in this way. Selecting the Modifier update checkbox in conjunction with Upsert enables this mode of updating. Selecting the Multi-update checkbox as well enables each update to apply to all matching documents (rather than just the first). At present, the MongoDB output step supports the $set, $inc and $push modifier operations. Furthermore it supports the positional operator ($) for matching inside of arrays.
For example, say we wanted to update Noddy's surname and increment his age using the following data:
first,last,address,age Noddy,Marionette,"Noddy Land",366
The following screenshot shows mongo document field configuration to achieve this using modifier updates. 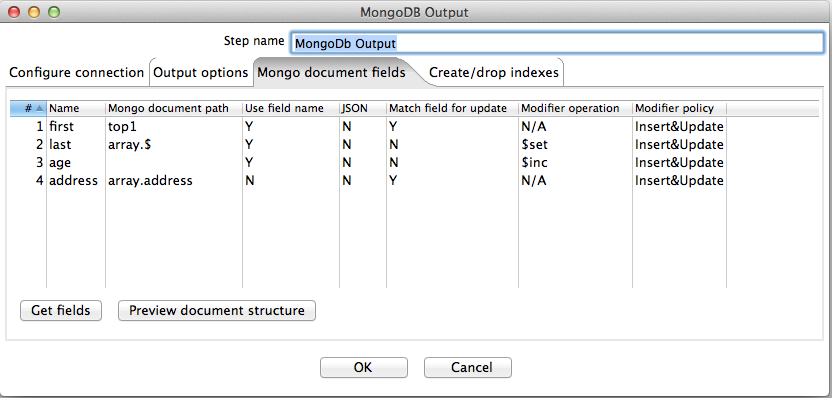
In this setup we're using the first name (first) and address fields to find the document(s) that we want to update. Because we are matching on the address field which resides in a record inside of an array, and one of the fields we want to mutate (last) also exists in the array, the document path for the lastname modifier operation uses the positional operator ($) to reference the position of the matched array item.
Modifier Policy
Control over when a modifier operation affecting a particular field gets executed can be achieved by specifying the Modifier Policy. By default this is set to "Insert&Update", meaning that the operation gets executed whether a match exists in the collection (according to the match conditions) or not. The policy can be set to "Insert" or "Update", where the former means the operation will be executed on an insert only (i.e. if the match conditions fail) and the latter on an update only (i.e. if that match conditions succeed). This can be particularly useful when the data for one Mongo document is split over several incoming PDI rows and in situations where it is not possible to execute different modifier operations that affect the same field simultaneously.
Consider a slight modification to our previous example where we have the following data and desired document structure:
first,last,service_id,address,age Sid,Smith,si77,"Lunar City",50 Sid,Smith,si77,"Mars Outpost",45
{
"first" : "<string val>",
"last" : "<string val>",
"service" : [
{
"service_id" : "<string val>",
"last" : "<string val>",
"residence" : [
{
"age" : "<integer val>",
"address" : "<string val>"
}
]
}
]
}
We can see that, 1) the data for a single document is split over two rows and, 2) our document has an array of records within an outer array of records. Assuming that residences are associated with a particular service ID for a given individual, then the match conditions are "first" and "last" in the top-level record and "service_id" in the records contained in the "service" array. For our data we want the "address" and "age" fields to be grouped into records that get appended (i.e. $push-ed) to the end of the residence array. $push by itself is not sufficient to handle this situation and will fail to create the structure we want when a particular individual is not already in the collection. I.e. $push-ing to service.0.residence will create the "residence" array in the case where the individual in question does not exist in the collection, but it will not create "service" as an array (because Mongo does not know whether "0" refers to a field name or an array index). The solution is to use $set operations to create the initial array structures when an individual does not exist (i.e. insert only) and $push operations to append to terminal arrays in the case when the individual does exist (i.e. update only).
The following screenshot shows the document field configuration to achieve the correct result for this example. That is, one record for Sid with two entries in the "residence" array.
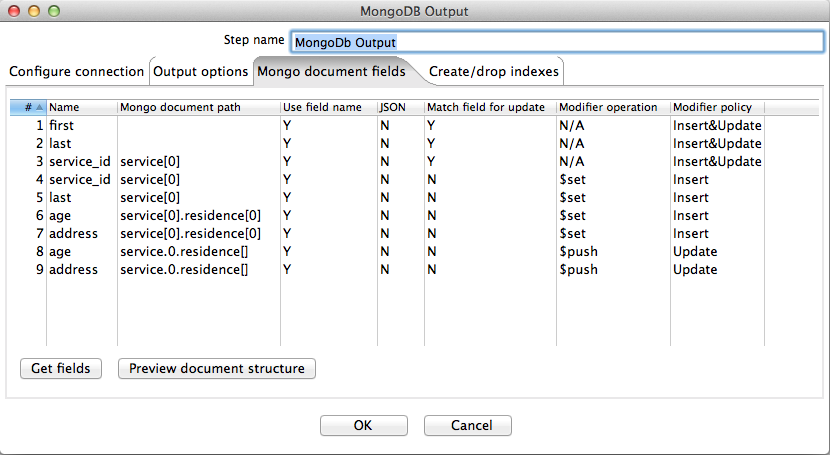
$set operations are used to create the bulk of our initial document structure for a new individual and then $push is used for array updates for existing individuals. There is additional overhead in this situation because it is necessary to query Mongo, with respect to the match fields, to see whether the current row will actually result in an insert or update. This example also demonstrates how to create paths that use modifier operations to $set or $push whole records into arrays. The step scans for arrays in the document paths and groups all operations of a particular type together for a common path prefix. So all "service[0]" are grouped for the $set operation in order to create the "service" array and set the record at index 0; similarly, all "service.0.residence" are grouped for the $push operation - the "[]" (no index required since $push always appends) tells the step that the grouped terminal fields are to be pushed together in a record.
An important difference between Mongo' standard upsert and modifier upserts is that, for the latter, the fields used to query for a match get created in the case when the match fails and an insert is performed. For a normal upsert, the match fields just locate a matching document (if any) and a complete object replacement is done. This makes it impossible to do certain modifier operations in the case where an insert actually occurs. In the above example we used "service[0].service_id" ia a query match field. The step automatically strips off the "[]" in order to convert this into the correct "dot" notation for the match - i.e. "service.0.service_id". If we were to combine this with a singe $push operation to append to the "service" array it would fail in the insert case with a "Cannot apply $push/$pushAll modifier to non-array" error. This is because the query fields get created first, which results in "service" being created as a record with a field called "0"- hence the error.
Create and Drop Indexes Tab
The MongoDb output step can create and/or drop indexes on one or more fields. Because indexing is an expensive operation it is performed after all rows have been processed by the step. The Create/drop indexes tab allows the user to specify which indexes to create (or remove). Each row in the table can be used to create a single index (using one field) or a compound index (using multiple fields). The "dot" notation is used to specify a path to a field to use in the index. This path can be optionally postfixed by a direction indicator. Compound indexes are specified by a comma-separated list of paths. The following screen shot shows the specification of a compound index on the "first" and "age" fields. It also shows the index information available through pressing the Show indexes button.
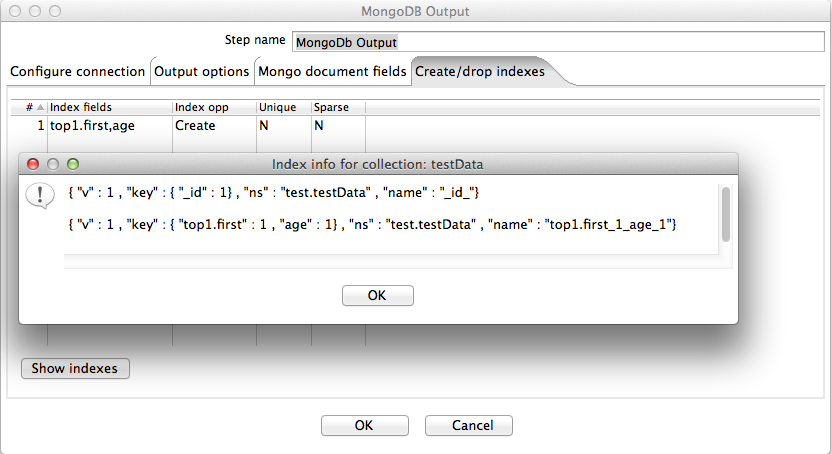
Indexes can be made sparse and/or unique by specifying "Y" in the corresponding column in the table.
Metadata Injection Support (7.x and later)
All fields of this step support metadata injection. You can use this step with ETL Metadata Injection to pass metadata to your transformation at runtime.