Cassandra Input
![]() PLEASE NOTE: This documentation applies to an earlier version. For the most recent documentation, visit the Pentaho Enterprise Edition documentation site.
PLEASE NOTE: This documentation applies to an earlier version. For the most recent documentation, visit the Pentaho Enterprise Edition documentation site.
Description
The Cassandra Input step enables data to be read from a Cassandra column family (table) using CQL.
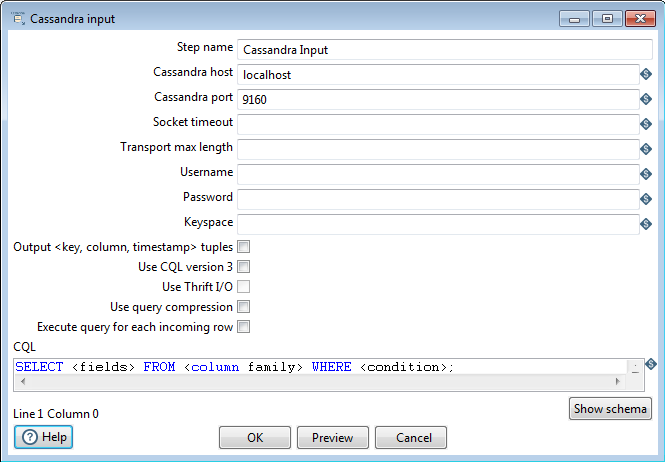
Options
Option | Definition |
|---|---|
Step name | The name of this step as it appears in the transformation workspace. |
Cassandra host | Cassandra server's host name input. |
Cassandra port | Cassandra server's host port number. |
Socket timeout | Sets an optional connection timeout period, specified in milliseconds. |
Transport max length | Sets an optional maximum object size that can be sent. |
Username | Input field for target keyspace and/or family (table) authentication details. |
Password | Input field for target keyspace and/or family (table) authentication details. |
Keyspace | Input field for the keyspace (database) name. |
Output tuples | If checked, provides tuple outputs for key, column and time stamp. |
Use CQL version 3 | If checked, uses CQL version 3. |
Use Thrift I/O | If checked, uses Thrift I/O. |
Use query compression | If checked, tells the step whether or not to compress the text of the CQL query before sending it to the server. |
Execute query for each incoming row | If checked, executes a query for each input row. |
Show schema | Opens a dialog that shows metadata for the column family named in the CQL SELECT query. |
CQL SELECT query
The large text box at the bottom of the dialog allows the user to enter a CQL SELECT statement to be executed. Only a single SELECT query is accepted by the step.
SELECT [FIRST N] [REVERSED] <SELECT EXPR> FROM <COLUMN FAMILY> [USING <CONSISTENCY>] [WHERE <CLAUSE>] [LIMIT N];
Important: Cassandra Input does not support the CQL range notation, for instance name1..nameN, for specifying columns in a SELECT query.
Select queries may name columns explicitly (in a comma separated list) or use the * wildcard. If the wildcard is used then only those columns defined in the metadata for the column family in question are returned. If columns are selected explicitly, then the name of each column must be enclosed in single quotation marks. Because Cassandra is a sparse column oriented database, as is the case with HBase, it is possible for rows to contain varying numbers of columns which might or might not be defined in the metadata for the column family. The Cassandra Input step can emit columns that are not defined in the metadata for the column family in question if they are explicitly named in the SELECT clause. Cassandra Input uses type information present in the metadata for a column family. This, at a minimum, includes a default type (column validator) for the column family. If there is explicit metadata for individual columns available, then this is used for type information, otherwise the default validator is used.
Option | Definition |
|---|---|
LIMIT | If omitted, Cassandra assumes a default limit of 10,000 rows to be returned by the query. If the query is expected to return more than 10,000 rows an explicit LIMIT clause must be added to the query. |
FIRST N | Returns the first N (where N is determined by the column sorting strategy used for the column family in question) column values from each row, if the column family in question is sparse then this may result in a different N (or less) column values appearing from one row to the next. Because PDI deals with a constant number of fields between steps in a transformation, Cassandra rows that do not contain particular columns are output as rows with null field values for non-existent columns. Cassandra's default for FIRST (if omitted from the query) is 10,000 columns. If a query is expected to return more than 10,000 columns, then an explicit FIRST must be added to the query. |
REVERSED | Option causes the sort order of the columns returned by Cassandra for each row to be reversed. This may affect which values result from a FIRST N option, but does not affect the order of the columns output by Cassandra Input. |
WHERE clause | Clause provides for filtering the rows that appear in results. The clause can filter on a key name, or range of keys, and in the case of indexed columns, on column values. Key filters are specified using the KEY keyword, a relational operator (one of =, >, >=, <, and <=) and a term value. |
More details on the WHERE clause
When terms appear on both sides of a relational operator it is assumed the filter applies to an indexed column. With column index filters, the term on the left of the operator is the name, the term on the right is the value to filter on. When filtering on indexed columns, there must be at least one equality operator present. Note that using inequality operators result in ranges that are inclusive of the terms (i.e. > is the same as >=, and < is the same as <=).
A WHERE clause may be used to filter rows that appear in the results.
SELECT ... WHERE KEY = keyname AND name1 = value1
SELECT ... WHERE KEY >= startkey and KEY =< endkey AND name1 = value1
SELECT ... WHERE KEY IN ('<key>', '<key>', '<key>', ...)
The Show schema button
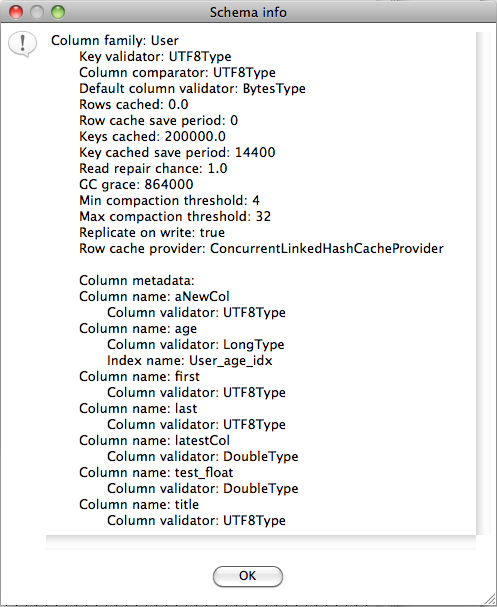
Displays meta data for the column family named in the CQL SELECT query.
Metadata Injection Support (7.x and later)
All fields of this step support metadata injection. You can use this step with ETL Metadata Injection to pass metadata to your transformation at runtime.