Pig Script Executor
Executes a script written in Apache Pig's "Pig Latin" language on a Hadoop cluster. All log entries pertaining to this script execution that are generated by Apache Pig will show in the PDI log.
Note: When you want to catch failing pig scripts with a false status return, you need to check the option "Enable blocking" otherwise the job entry does not wait and cannot get the Pig script result. (working since 7.0, see PDI-11935)
Configuring Hadoop connection details
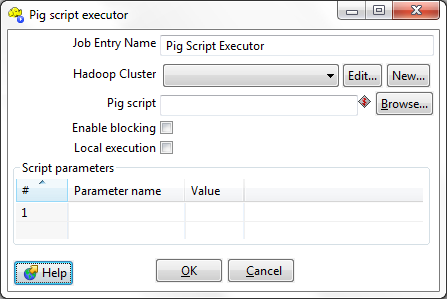
The screenshot below shows the Pig Script Executor GUI dialog. The primary configuration details include Hadoop connection information, the pig script to run and parameters (if any) in the script that should be substituted with corresponding values.
The HDFS hostname and HDFS port fields allow the user to specify the name of the machine and port number that the Hadoop cluster's distributed file system can be accessed at. Below these the Job tracker hostname and Job tracker port enable the user to supply similar information for the machine at which Hadoop's job tracker can be accessed.
Option |
Definition |
|---|---|
Job Entry Name |
The name of this Pig Script Executor instance. |
Hadoop Clusters |
Allows you to create, edit, and select a Hadoop cluster configuration for use. Hadoop cluster configurations settings can be reused in transformation steps and job entries that support this feature. In a Hadoop cluster configuration, you can specify information like host names and ports for HDFS, Job Tracker, and other big data cluster components. The Edit button allows you to edit Hadoop cluster configuration information. The New button allows you to add a new Hadoop cluster configuration. Information on Hadoop Clusters can be found in Pentaho Help. |
Pig script |
The path (remote or local) to the Pig Latin script you want to execute. |
Enable blocking |
If checked, the Pig Script Executor job entry will prevent downstream entries from executing until the script has finished processing.
|
Local execution |
Executes the script within the same Java virtual machine that PDI is running in. This option is useful for testing and debugging because it does not require access to a Hadoop cluster. When this option is selected, the HDFS and job tracker connection details are not required and their corresponding fields will be disabled. |
Hadoop Cluster
The Hadoop cluster configuration dialog allows you to specify configuration detail such as host names and ports for HDFS, Job Tracker, and other big data cluster components, which can be reused in transformation steps and job entries that support this feature.Option | Definition |
|---|---|
Cluster Name | Name that you assign the cluster configuration. |
Use MapR Client | Indicates that this configuration is for a MapR cluster. If this box is checked, the fields in the HDFS and JobTracker sections are disabled because those parameters are not needed to configure MapR. |
Hostname (in HDFS section) | Hostname for the HDFS node in your Hadoop cluster. |
Port (in HDFS section) | Port for the HDFS node in your Hadoop cluster. |
Username (in HDFS section) | Username for the HDFS node. |
Password (in HDFS section) | Password for the HDFS node. |
Hostname (in JobTracker section) | Hostname for the JobTracker node in your Hadoop cluster. If you have a separate job tracker node, type in the hostname here. Otherwise use the HDFS hostname. |
Port (in JobTracker section) | Port for the JobTracker in your Hadoop cluster. Job tracker port number; this cannot be the same as the HDFS port number. |
Hostname (in ZooKeeper section) | Hostname for the Zookeeper node in your Hadoop cluster. |
Port (in Zookeeper section) | Port for the Zookeeper node in your Hadoop cluster. |
URL (in Oozie section) | Field to enter an Oozie URL. This must be a valid Oozie location. |
Script execution options
The Pig script field is used to specify the path to a Pig Latin script to be executed. In the above screenshot, the job entry has been configured to connect to a Hadoop cluster where both the distributed file system and the job tracker are accessed at the host "hadoop-vm3". The script to be executed is one that is described in the Pig tutorial (http://pig.apache.org/docs/r0.8.0/tutorial.html) and can be found in the samples directory of your PDI installation (samples/jobs/hadoop). The only modification to this script, compared to the original, is to make the path to the user defined functions (UDF) "tutorial.jar" into a script parameter, rather than hard-coded in the script.
Below the Pig script field is a check box entitled Enable blocking. Selecting this means that the Pig Script Executor job entry will prevent downstream entries from executing until the pig script has finished processing. Unselecting this will launch the script and then continue immediately to any further job entries. The Local execution check box enables the pig script to be executed entirely within the same Java virtual machine that PDI is running in. This option is useful for testing and debugging as it does not require access to a Hadoop cluster. When this option is selected the HDFS and job tracker connection details are not required and their corresponding fields are disabled in the UI.
Option |
Definition |
|---|---|
# |
The order of execution of the script parameters. |
Parameter name |
The name of the parameter you want to use. |
Value |
The value you're substituting whenever the previously defined parameter is used. |
Monitoring execution
The Pig Script Executor has access to Pig's logging mechanism and will display all Pig's log messages, and all of Hadoop's log messages (as passed on by Pig), in PDI's log.
See Also
Troubleshooting: Pig Job Not Executing After Kerberos Authentication Fails