HBase Output
![]() PLEASE NOTE: This documentation applies to an earlier version. For the most recent documentation, visit the Pentaho Enterprise Edition documentation site.
PLEASE NOTE: This documentation applies to an earlier version. For the most recent documentation, visit the Pentaho Enterprise Edition documentation site.
Description
This step writes data to an HBase table according to user-defined column metadata.
Options
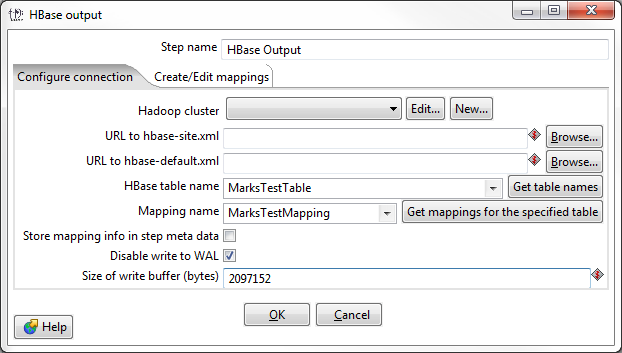
Configure Connection Tab
This tab contains HBase connection information. You can configure a connection in one of two ways: using the Hadoop cluster properties, or by using an hbase-site.xml and (an optional) hbase-default.xml configuration file.
Below the connection details are fields to specify the target HBase table to write to and a mapping by which to encode incoming field values. Before a value can be written to HBase it is necessary to tell the step which column family it belongs to and what its type is. Furthermore, it is necessary to specify type information about the key of the table. This is where a mapping comes into play and the user must define a mapping to use for a new or given target table.
Option | Definition |
|---|---|
Step name | The name of this step as it appears in the transformation workspace. |
Hadoop Cluster | Allows you to create, edit, and select a Hadoop cluster configuration for use. Hadoop cluster configurations settings can be reused in transformation steps and job entries that support this feature. In a Hadoop cluster configuration, you can specify information like host names and ports for HDFS, Job Tracker, and other big data cluster components. The Edit button allows you to edit Hadoop cluster configuration information. The New button allows you to add a new Hadoop cluster configuration. Information on Hadoop Clusters can be found in Pentaho Help. |
URL to hbase-site.xml | Address of the |
URL to hbase-default.xml | Address of the |
HBase table name | The HBase table to write to. Click Get Mapped Table Names to populate the drop-down list of possible table names. |
Mapping name | A mapping to decode and interpret column values. Click Get Mappings For the Specified Table to populate the drop-down list of available mappings. |
Store mapping info in step meta data | Indicates whether to store mapping information in the step's meta data instead of loading it from HBase when it runs. |
Disable write to WAL | Disables writing to the Write Ahead Log (WAL). The WAL is used as a lifeline to restore the status quo if the server goes down while data is being inserted. Disabling WAL will increase performance. |
Size of write buffer (bytes) | The size of the write buffer used to transfer data to HBase. A larger buffer consumes more memory (on both the client and server), but results in fewer remote procedure calls. The default (in the hbase-default.xml) is 2MB (2097152 bytes), which is the value that will be used if the field is left blank. |
Hadoop Cluster
The Hadoop cluster configuration dialog allows you to specify configuration detail such as host names and ports for HDFS, Job Tracker, and other big data cluster components, which can be reused in transformation steps and job entries that support this feature.
Option | Definition |
|---|---|
Cluster Name | Name that you assign the cluster configuration. |
Use MapR Client | Indicates that this configuration is for a MapR cluster. If this box is checked, the fields in the HDFS and JobTracker sections are disabled because those parameters are not needed to configure MapR. |
Hostname (in HDFS section) | Hostname for the HDFS node in your Hadoop cluster. |
Port (in HDFS section) | Port for the HDFS node in your Hadoop cluster. |
Username (in HDFS section) | Username for the HDFS node. |
Password (in HDFS section) | Password for the HDFS node. |
Hostname (in JobTracker section) | Hostname for the JobTracker node in your Hadoop cluster. If you have a separate job tracker node, type in the hostname here. Otherwise use the HDFS hostname. |
Port (in JobTracker section) | Port for the JobTracker in your Hadoop cluster. Job tracker port number; this cannot be the same as the HDFS port number. |
Hostname (in ZooKeeper section) | Hostname for the Zookeeper node in your Hadoop cluster. |
Port (in Zookeeper section) | Port for the Zookeeper node in your Hadoop cluster. |
URL (in Oozie section) | Field to enter an Oozie URL. This must be a valid Oozie location. |
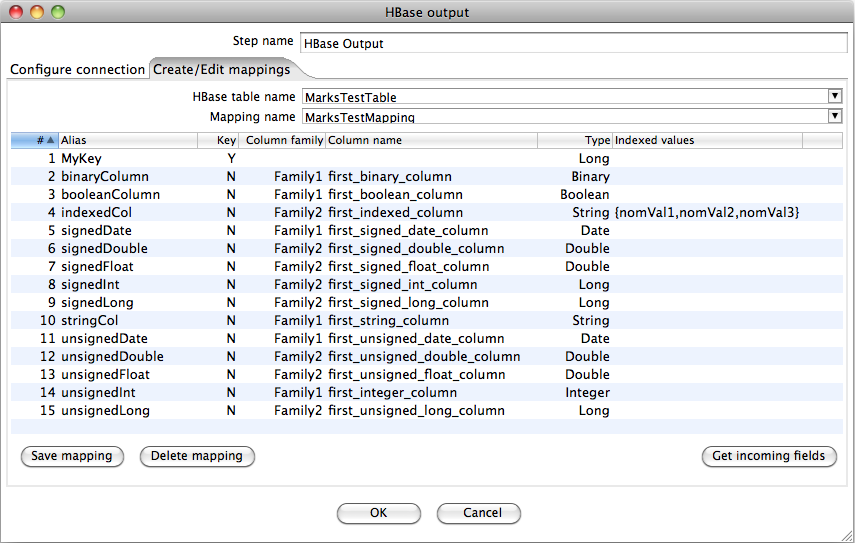
Create and Edit Mappings Tab
This tab creates or edits a mapping for a given HBase table. A mapping simply defines metadata about the values that are stored in the table. Since just about all information is stored as raw bytes in HBase, this allows PDI to decode values and execute meaningful comparisons for column-based result set filtering. Names of fields entering the step are expected to match the aliases of fields defined in the mapping. All incoming fields must have a matching counterpart in the mapping. There may be fewer incoming fields than defined in the mapping, but if there are more incoming fields then an error will occur. One of the incoming fields must match the key defined in the mapping.
This tab operates in the same way as it does in the HBase Input step, with the exception that it allows the target HBase table to be created if it doesn't already exist. Furthermore, the fields coming into the step can be used as the basis for defining a mapping.
Selecting a table will populate the Mapping name drop-down box with the names of any mappings that exist for the table. This box will be empty if there are no mappings defined for the selected table and the user can enter the name of a new mapping. The fields area of the tab can be used to enter information about the columns in the HBase table that the user wants to map. Selecting the name of an existing mapping will load the fields defined in that mapping into the fields area of the display. Alternatively, if the user can create a new HBase table and mapping for it simultaneously by configuring the fields of the mapping and entering the name of a table that doesn't exist in the Hbase table name drop down box.
Option | Definition |
|---|---|
HBase table name | Displays a list of table names. Connection information in the previous tab must be valid and complete in order for this drop-down list to populate. See Note in the performance considerations section for more options |
Mapping name | Names of any mappings that exist for the table. This box will be empty if there are no mappings defined for the selected table, in which case you can enter the name of a new mapping. |
# | The order of the mapping operation. |
Alias | The name you want to assign to the HBase table key. This is required for the table key column, but optional for non-key columns. |
Key | Indicates whether or not the field is the table's key. |
Column family | The column family in the HBase source table that the field belongs to. Non-key columns must specify a column family and column name. |
Column name | The name of the column in the HBase table. |
Type | Data type of the column. Key columns can be of type: String Integer Unsigned integer (positive only) Long Unsigned long (positive only) Date Unsigned date. |
Indexed values | String columns may optionally have a set of legal values defined for them by entering comma-separated data into this field. |
Get incoming fields | Retrieves a field list using the given HBase table and mapping names. |
A valid mapping must define meta data for at least the key of the source HBase table. The key must have an Alias specified because there is no name given to the key of an HBase table. Non-key columns must specify the Column family that they belong to and the Column name. An*Alias* is optional - if not supplied then the column name is used. All fields must have type information supplied.
To enable meaningful range scans over key values it is necessary for keys to sort properly in HBase. This is why we make a distinction between unsigned and signed numbers. Since HBase stores integers/longs in twos complement internally it is necessary to flip the sign bit before storing a signed number in order to have positive numbers sort after negative ones. Unsigned integers/longs are assumed to have been stored directly without without inverting the sign bit. Note that keys that are dates are assumed to have been stored as just signed or unsigned longs (i.e. number of milliseconds elapsed since the epoch). If you have a key that is date in string format (ISO 8601 date-time format is designed such that lexicographic order corresponds to chronological order) it can be mapped as type String and then PDI can be used to change the type to Date for manipulation in the transformation.
No distinction is made between signed and unsigned numbers here because no sorting is performed by HBase on anything other than the key. Boolean values may be stored in HBase as 0/1 integer/long or as strings (Y/N, yes/no, true/false, T/F). BigNumber may be stored as either a serialized BigDecimal object or in string form (i.e. a string that can be parsed by BigDecimal's constructor). Serializable is any serialized Java object and Binary is a raw array of bytes. String columns may optionally have a set of legal values defined for them by entering comma-separated data into the Indexed values column in the fields table.
Pressing the Save mapping button will save the mapping. If the target table does not exist, then the user will be asked if they want to use key and column family information from the mapping as the basis for the structure of the new table. The user will also be alerted to any missing information in the mapping definition and prompted to rectify it before the mapping is actually saved. Note that it is possible to define multiple mappings - involving different subsets of columns - on the same HBase table. The Delete mapping button allows the current named mapping for the current named table to be deleted from the mapping table. Note that this does not delete the actual HBase table in question.
To speed up the creation of a mapping it is possible to use the incoming fields to the step as the basis for the mapping. Pressing the Get incoming fields button will populate the mapping table with information from the fields entering the step. The Alias and Column name of each mapping field will be set to the name of an incoming field, the type information will be filled in automatically, and the Column family will be set to either the name of the first column family defined if the table already exists, or, a default value ("Family1"), which can be altered by the user to define their own families when the target table is created. Note that the step does not support adding new column families to an existing table.
IMPORTANT: The names of fields entering the step are expected to match the aliases of fields defined in the mapping. All incoming fields must have a matching counterpart in the mapping. There may be fewer incoming fields than defined in the mapping but if there are more incoming fields then an error will be raised. Furthermore, one of the incoming fields must match the key defined in the mapping.
Performance Considerations
HBase server configuration and tuning aside, there are several things to consider when using HBase Output. The Configure connection tab provides a field for setting the size of the write buffer used to transfer data to HBase. The user may enter a number here (in bytes). A larger buffer consumes more memory (on both the client and server sides) but results in fewer remote procedure calls. The default (in the hbase-default.xml) is 2Mb (2097152 bytes) and this value will be used if the field is left blank. When left blank, auto flush is enabled and "Put" operations are executed immediately. This means that each row will be transmitted to HBase at the time it arrives at the step. Entering a number (even if it is the same as the default) for the size of the write buffer will disable auto flush and will result in incoming rows only being transferred once the buffer is full.
There is also a check box for disabling writing to the Write Ahead Log (WAL). The WAL is used as a lifeline to restore the status quo if the server goes down while data is being inserted. However, the tradeoff for error-recovery is speed.
NOTE: The Create/edit mappings tab allows the user to specify some options for when a new table is created in HBase. In the HBase table name field the user may optionally suffix the name of the new table with parameters for specifying what compression to use and whether or not to use Bloom filters to speed up lookups. The options for compression include NONE, GZ and LZO; the options for Bloom filters include NONE, ROW, ROWCOL. If nothing is specified - beyond the name of the new table - by the user, then the default of NONE is used for both compression and Bloom filters. For example, the following string entered in the HBase table name field specifies that a new table called "NewTable" should be created with GZ compression and ROWCOL Bloom filters:
NewTable@GZ@ROWCOL
Note that due to licensing constraints, HBase does not ship with LZO compression libraries - these must be installed on each node by the user if they wish to use LZO compression.
Metadata Injection Support (7.x and later)
All fields of this step support metadata injection. You can use this step with ETL Metadata Injection to pass metadata to your transformation at runtime.