Partitioning data with PDI
Partitioning data with PDI
Partitioning simply splits a data set into a number of sub-sets according to a rule that is applied on a row of data. This rule can be anything you can come up with and this includes no rule at all. However, if no rule is applied we simply call it (round robin) row distribution. You can create your own rules in the form of a partitioning method plugin.
The reason for partitioning data up is invariably linked to parallel processing since it makes it possible to execute certain tasks in parallel where this is otherwise not possible.
Partitioning to facilitate parallel processing
Suppose you want to aggregate data by state, you can do an in-memory aggregation like this:
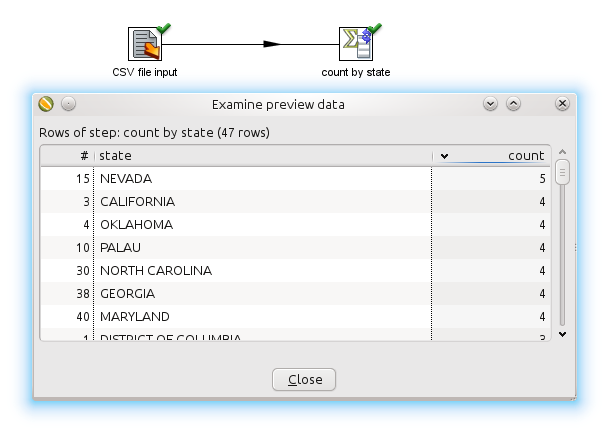
Reading the data from the CSV file is something we can do in parallel. However if you would aggregate in parallel you would see incorrect results: 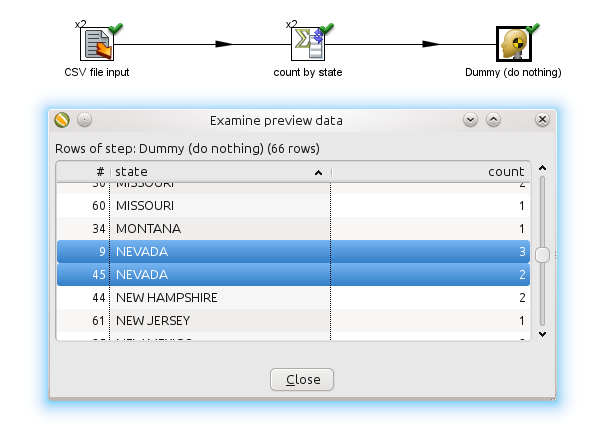
This is obviously because the rows are split up arbitrarily (without a specific rule) over the 2 copies of the "count by state" aggregation step.
What we need is a simple way to direct rows from the same state to the same step copy. This rule-based direction is what is we call "partitioning".
In the example below we created a new partitioning schema called "State" that is applied to the "count by state" step. We selected "Remainder of division" partitioning rule applied to the "state" field. Please note that in case the modulo (remainder of division) is calculated on a non-integer value Kettle actually calculates the modulo on a checksum created from the String, Date, Number value in question. As long as rows with the same state value are sent to the same step copy and if the distribution of the rows is about fair among the steps we don't care. (see PDI-5514 for a fixed bug on partitioning on negative values)
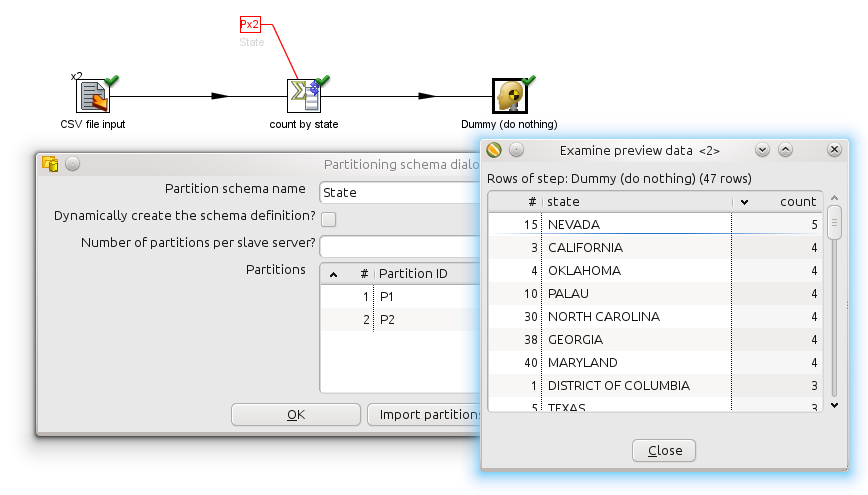
The example above can be found in file "samples/transformations/General - parallel reading and aggregation.ktr" of your PDI distribution, version 4.2 or later.
Re-partitioning logic
In the next image we show how the data is distributed in the steps:

As you can see, the "CSV Input" step nicely divides the work between 2 step copies and each copy nicely reads 50 rows of data. However, these 2 step copies also need to make sure that the rows end up on the correct "count by state" step copy where they arrive in a 43/57 split. Because of that it's a general rule that the step that performs the re-partitioning of the data (a non-partitioned step before a partitioned one) has internal buffers from every source step copy to every target step copy as shown in the following image: 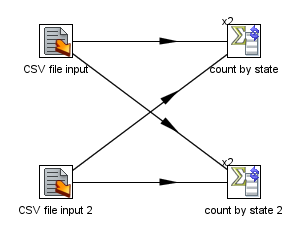
If you would have 3 step copies reading our file and 4 partitions, Kettle will internally allocate buffers (row sets) as shown in the following image: 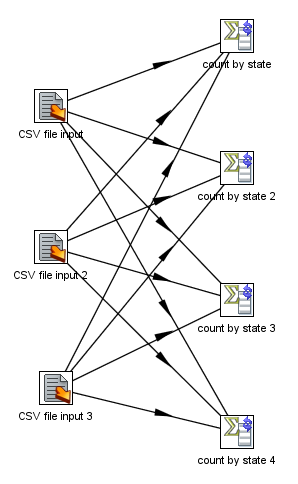
Swim-lanes
When a partitioned step passes data to one another partitioned step and the partitioning schema is the same, Kettle will keep the data in so called swimming lanes.
For example, take the following example: 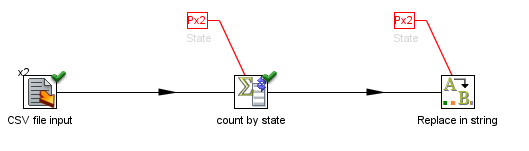
This will internally be executed as follows:
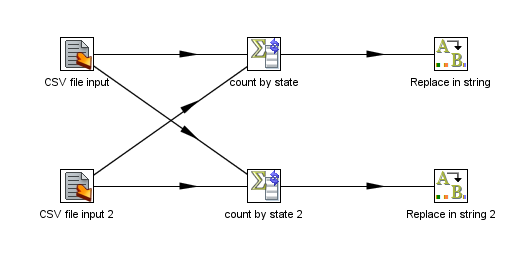
As you can see, no re-partitioning needs to be done, so no extra buffers (row sets) are allocated between the copies of steps "count by state" and "Replace in string". The step copies are as such totally isolated from one another. The rows of data are as such located in one of the so called data "swimming lanes" and they will continue to be in the same lane as long as the steps following are partitioned with the same partitioning schema. No extra work needs to be done to keep data partitioned so you can chain as many partitioned steps as you like.
The rules
Based on the examples above we can formulate the following rules:
- A partitioned step causes on step copy to be executed per partition in the partition schema
- When a step needs to re-partition the data it creates buffers (row sets) from each source step copy to each target step copy (partition)
Please note that while having a lot of buffers is a necessity it can cause memory usage problems if all the buffers fill up.
On the topic of when data is re-partitioned we also have a few rules of thumb:
- When rows of data pass from a non-partitioned step to a partitioned one, data is re-partitioned and extra buffers are allocated.
- When rows of data pass from a partitioned step to another partitioned step, partitioned with the same partition schema, data is not re-partitioned.
- When rows of data pass from a partitioned step to another partitioned step, partitioned with another partition schema, data is re-partitioned.
Clustering and partitioning
When a step is assigned to run on a master (non-clustered in a clustered transformation) the same rules apply as shown above.
In case a clustered step is partitioned, the partitions are distributed over the number of slave servers. Because of this there is a general rule that the number of partitions needs to be equal to or higher than the number of slave servers in the cluster schema.
Because of this general rule it's easier to have Kettle create the partition schema dynamically in a clustered environment.
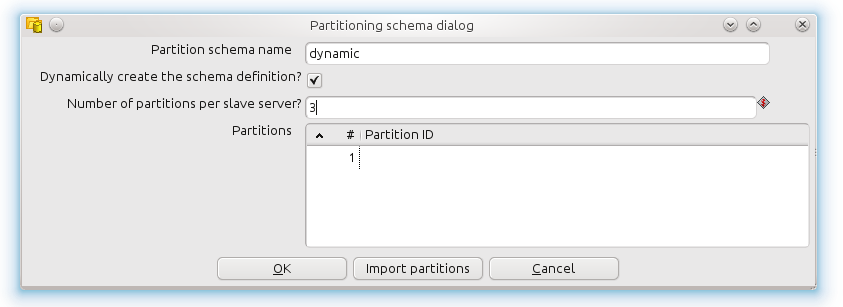
Please make sure to limit re-partitioning on a cluster to a minimum since this incurs a serious networking and CPU overhead. That is caused by the massive passing of data from one server to another over TCP/IP sockets. Try to keep the data in swimming lanes as shown above, for as long as possible, to get optimal performance on a cluster.