Greenplum Load
Description
The Greenplum Load step wraps the Greenplum GPLoad data loading utility. The GPLoad data loading utility is used for massively parallel data loading using Greenplum's external table parallel loading feature. Typical deployment scenarios for performing parallel loading to Greenplum include:
Single ETL Server, Multiple NICs
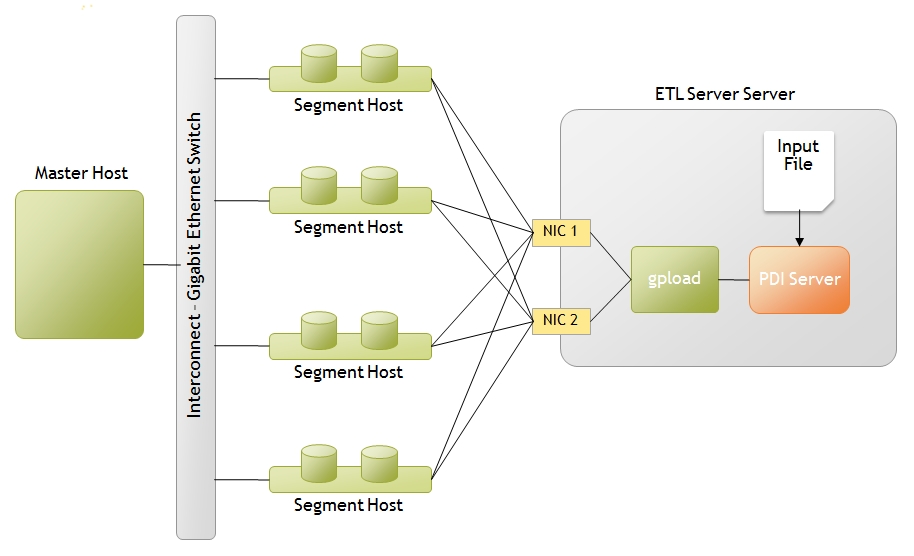
This deployment highlights a scenario where you have a single ETL server with two Network Interface Cards (NICs )and you want to perform parallel data loading across the NICs. A simple transformation then to load data from the input file (located on the ETL Server) in parallel would look like the following:
![]()
The Greenplum load step would be configured with a local hostname definition for each NIC on the server. When executed, PDI will generate the necessary YAML control file:
VERSION: 1.0.0.1
DATABASE: foodmart
USER: gpadmin
HOST: 192.168.1.42
PORT: 5432
GPLOAD:
INPUT:
- SOURCE:
LOCAL_HOSTNAME:
- etl1-1
- etl1-2
FILE: ['load0.dat']
- FORMAT: TEXT
- DELIMITER: ','
- QUOTE: ''
- HEADER: FALSE
- ERROR_LIMIT: 50
- ERROR_TABLE: err_customer
OUTPUT:
- TABLE: samples_customer
- MODE: insert
and the data file. gpload is executed using the following command:
/user/local/greenplum-db/bin/gpload -f control10.dat
Multiple ETL Servers
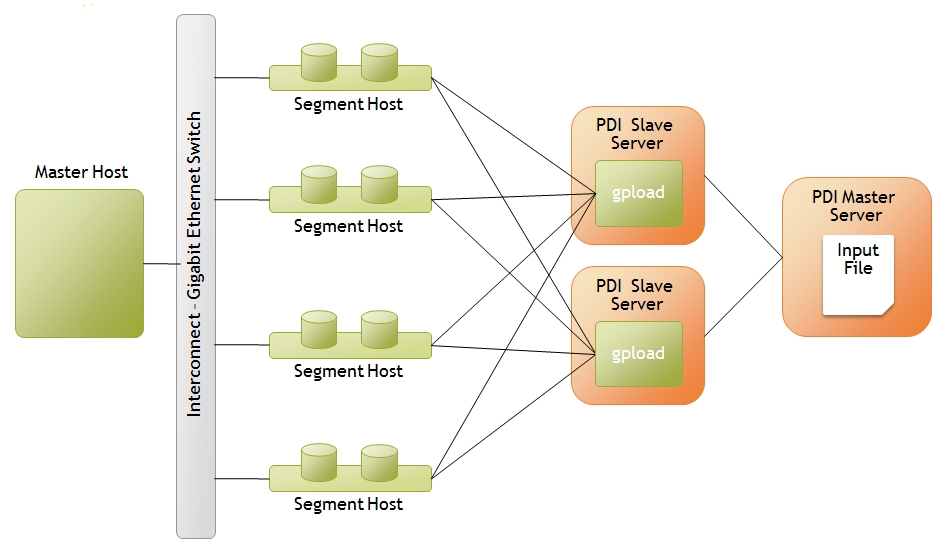
This scenario depicts where there are several physical ETL servers and the PDI Transformation is to be executed in clustered mode. To setup this configuration, perform the following steps:
- Setup a cluster of three PDI servers, two slaves and one master
- Build a simple transformation reading from the input file (which needs to reside on the master node of your PDI cluster) and a Greenplum Load step
- Right-click on the Greenplum load step, select 'Clusterings...' and select the cluster you defined in step 1
You should now have a transformation similar to:
![]()
When executed, the PDI master will evenly distribute rows from the input file to each of the PDI slave servers which will in turn call gpload to load their portion of the data.
For information on how to install and configure GPload and GPfdist, please refer to the Greenplum Administration Guide.
Options
Option |
Description |
|---|---|
Step name |
Name of the step. |
Connection |
The database connection(JDBC) to which you will be loading data. Note that you must set $PGPASSWORD in the environment where gpload executes, the password is not transfered to the gpload process from kettle. |
Target schema |
The name of the Schema for the table to write data to. |
Target table |
The name of the target table to write data to. |
Load method |
Defines whether to actually call gpload (Automatic) after generating the configuration and data files or stop execution after the files are created (Manual) so that gpload could be run manually at a later time. |
Erase cfg/dat files after use |
Configure whether or not you want the control and data files generated to be removed after execution of the transformation. |
Fields Tab
Option |
Description |
|---|---|
Load action |
Defines the type of load you wish to perform: |
Get Field |
Click this button to retrieve a list of potential fields to load based on the input fields coming into this step. |
Edit Mapping |
Click this button to open the mapping editor allowing you to change the mapping between fields from the source data file and the corresponding field the data will be written to in the target table. |
Table Field |
Name of the column in the "Target Table" that maps to a "Stream field" |
Stream Field |
Name of a field input stream. The data in this field will be loaded into the database column specified by "Table Field". |
Date Mask |
The date mask to use of the "Stream Field" is a date type. |
Match |
Boolean. Setting to "Y" indicates that the column is to be used in the "match criteria" of the join condition of the update. |
Update |
Boolean. If set to ""Y then the column will be updated for the rows that meet the "match criteria". |
Update condition |
Optional. Specifies a Boolean condition, similar to what you would declare in a SQL WHERE clause, that must be met in order for a row in the target table to be updated or inserted, in the case of a MERGE. |
Local Host Names Tab
Option |
Description |
|---|---|
Port |
Optional. Specifies the specific port number that the gpfdist file distribution program should use. If not specified and Hostname(s) |
Hostname |
Optional. Specifies the host name or IP address of the local machine on |
GP Configuration tab
Option |
Description |
|---|---|
Path to the gpload |
The path to where the GPload utility is installed. |
Control file |
Defines the name of the GPload control file that will be generated.
control${Internal.Step.CopyNr}.cfg
|
Error table |
Defines the target table where error records will be written to. If the table exists it will not be truncated before the load. If the table does not exist it will be created. |
Maximum errors |
Defines the maximum number of errors to allow before the load operation is aborted. Erros are logged to the specified "Error Table". |
Log file |
Specify the location for where GPload will write log information. This information is what would be displayed in a terminal or window if gpload was executed at the command line. |
Data file |
Defines the name of the Data file(s) that will be written for subsequent loading in the target tables by GPload.
load${Internal.Step.CopyNr}.dat
|
Delimiter |
Delimits the fields written to "Data file". This delimiter is then specified in the generated control file. |
Encoding |
Specify the character set encoding of the data file. Supported encodings are: |
Example
The attached transformation, GPLoad-localhost-variables, demonstrates how environmental variables can be used in the Greenplum Load step to defined local hosts.
Metadata Injection Support (7.x and later)
All fields of this step support metadata injection. You can use this step with ETL Metadata Injection to pass metadata to your transformation at runtime.