Get Data from XML - Handling Large Files
When you want to read in large files the following ongoing is recommended
- Create a smaller file if you want to use the "Get XPath nodes" or "Get Fields"buttons (it simplifies your life a lot).
- Define the property "Prune path to handle large files". When the prune path is given, the file is processed in a streaming mode in chunks of data separated by the prune path. At first this can be almost the same as the "Loop XPath" property with some exceptions:
- Only node names and slashes are allowed here (if your document and Loop XPath includes namespaces, do not enter them here)
- You can define the prune path different to the Loop XPath and start at a higher level, examples are below.
- Memory considerations: About one percent of the file size is needed as memory when you prune at the lowest level. That means for a 1GB file, you would need about 100MB of extra memory what is normally within the range of the default Java VM setting of 256MB that we use. (If you need higher values, please chage the -Xmx256m option in your .bat or .sh files.)
Notes:
- When detailed logging is activated you will see log entries of: "Streaming mode for processing large XML files is activated."
- Ensure to disable debug logging for processing large files.
- The pruning (streaming) mode is not possible when "XML source is defined in a field" is activated.
- Do not prune at lower levels then the Loop XPath... otherwise you get too much elements.
How to tweak the performance and processing by using different levels of the prune path?
For instance the following document structure has to be processed (small sample is attached):
<?xml version="1.0" encoding="UTF-8"?>
<AllRows>
<Rows rowID="1">
<Row><v1>abc[...]</v1> <v2>abc[...]</v2> <v3>abc[...]</v3> <v4>abc[...]</v4> <v5>abc[...]</v5> <v6>abc[...]</v6> <v7>abc[...]</v7> <v8>abc[...]</v8> <v9>abc[...]</v9> </Row>
<Row><v1>abc[...]</v1> <v2>abc[...]</v2> <v3>abc[...]</v3> <v4>abc[...]</v4> <v5>abc[...]</v5> <v6>abc[...]</v6> <v7>abc[...]</v7> <v8>abc[...]</v8> <v9>abc[...]</v9> </Row>
[...]
</Rows>
[...]
</AllRows>
Now think of the number of <Row> elements are about 100 MB and we have some more blocks (chunks) of these data. When you have 3 blocks you have a file with 300 MB, with 10 blocks you have a 1GB file.
You can download the Sample for a 300MB file with and without chunks of data
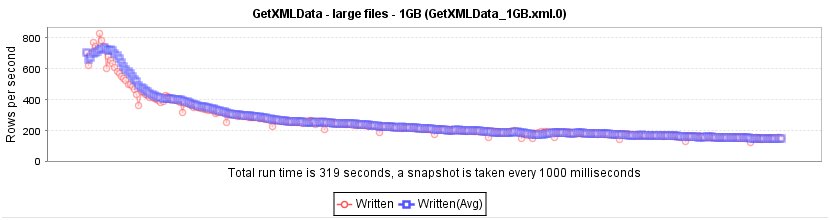
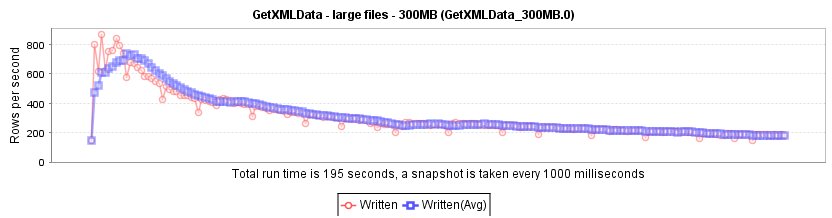
One option would be to use the prune path of /AllRows/Rows/Row (the same like in the Loop XPath). The result of the number of rows that are processed looks like this: We have a performance decrease (actually out of an unknown reason) that let's the rows per second decrease down to about 200 - well the 300MB file is still read in in about 200 seconds.
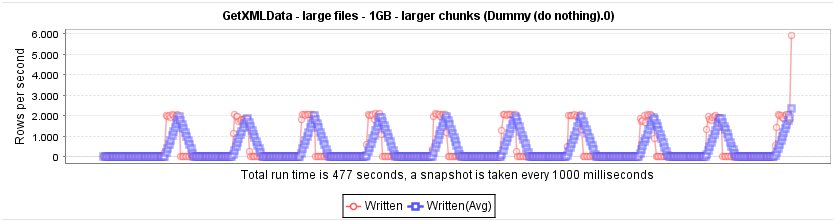
Another option would be to use the prune path of/AllRows/Rows and read in chunks of data in 100MB each, the result looks like this: The reader reads in a chunk of data and processed this with a speed of about 2000 rows per second. (At the end it peaks up a little bit.)
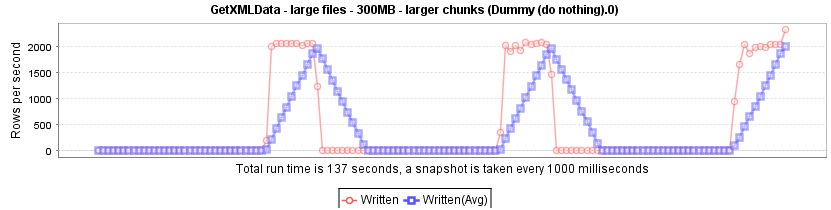
Out of this we did not automaically set the prune path to some inherited property of the Loop XPath, so you have the freedom to decide what the correct prune path should be for your type of file.
Just for reference that this is working with a 1 GB file, here are the corresponding graphics: At the first graphics the number of rows goes down to about 180 rows/sec and the next graphic shows a constant processing of about 2000 rows/sec for each chunk (again with the peak at the end that should be ignored).