Stream Lookup
Description
The Stream lookup step type allows you to look up data using information coming from other steps in the transformation. The data coming from the Source step is first read into memory and is then used to look up data from the main stream.
In the example below, the transformation adds information coming from a text-file (B) to data coming from a database table (A):
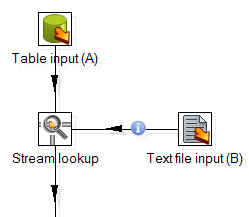
Information from B is used to perform the lookups as indicated by the Source step option shown below.
Note: Consider using the Database Lookup step when the Lookup step originates from a table. In this case, it is faster to use the Database Lookup step and enable the option Load all data from table that pre-loads the cache.
Options
The table below describes the features available for configuring the stream lookup:
Option | Description |
|---|---|
Step name | Name of the step this name has to be unique in a single transformation |
Lookup step | The step name where the lookup data is coming from |
The keys to lookup... | Allows you to specify the names of the fields that are used to look up values. Values are always searched using the "equal" comparison |
Fields to retrieve | You can specify the names of the fields to retrieve here, as well as the default value in case the value was not found or a new field name in case you didn't like the old one. Note: The Type of the Default value does only provide the data type for the conversion of the Default value. It does not convert the original type of the field. |
Preserve memory | Encodes rows of data to preserve memory while sorting. (Technical background: Kettle will store the lookup data as raw bytes in a custom storage object that uses a hashcode of the bytes as the key. More CPU cost related to calculating the hashcode, less memory needed.) |
Key and value are exactly one integer field | Preserves memory while executing a sort by . Note: Works only when "Preserve memory" is checked. Cannot be combined with the "Use sorted list" option. |
Use sorted list | Enable to store values using a sorted list; this provides better memory usage when working with data sets containing wide row. Note: Works only when "Preserve memory" is checked. Cannot be combined with the "Key and value are exactly one integer field" option. (Technical background: the lookup data is put into a tuple and stored in a sorted list. Lookups are done via a binary tree search.) |
Get fields | Automatically fills in the names of all the available fields on the source side (A); you can then delete all the fields you don't want to use for lookup. |
Get lookup fields | Automatically inserts the names of all the available fields on the lookup side (B). You can then delete the fields you don't want to retrieve |
Metadata Injection Support
All fields of this step support metadata injection. You can use this step with ETL Metadata Injection to pass metadata to your transformation at runtime.