Using the Knowledge Flow Plugin
Contents
1 Introduction
The Knowledge Flow plugin is an enterprise edition tool that allows entire data mining processes to be run as part of a Kettle (PDI) ETL transformation. There are a number of use cases for combining ETL and data mining, such as:
- Scheduled, automatic batch training/refreshing of predictive models
- Including data mining results in reports
- Access to data mining data pre-processing techniques in ETL transformations
Training/refreshing of predictive models is the application described in this document and, when combined with the Weka Scoring plugin for deploying predictive models, can provide a fully automated predictive analytics solution.
2 Requirements
The Knowledge Flow plugin requires Kettle 4.x and Weka 3.6 or higher.
3 Installation
Before starting Kettle's Spoon UI, the Knowledge Flow Kettle plugin must be installed in either the plugins/steps directory in your Kettle distribution or in $HOME/.kettle/plugins/steps. Simply unpack the "pdi-knowledgeflow-plugin-ee-deploy.zip" file in plugins/steps.
The Knowledge Flow Kettle plugin also requires a small plugin to be installed in the Weka Knowledge Flow application. This plugin provides a special data source component for the Weka Knowledge Flow that accepts incoming data sets from Kettle.
For Weka >= 3.7.2
Use Weka's built-in package manager (GUIChooser-->Tools) to install the package "kfKettle."
For Weka 3.6.x - 3.7.0
Unpacking the "pdi-knowledgeflow-plugin-ee-deploy.zip" file creates a "KFDeploy" directory and a "KettleInject" directory in the plugins/steps directory of your Kettle installation. Move the "KettleInject" directory to $HOME/.knowledgeFlow/plugins. If the $HOME/.knowledgeFlow/plugins directory does not exist, you will need to create it manually.
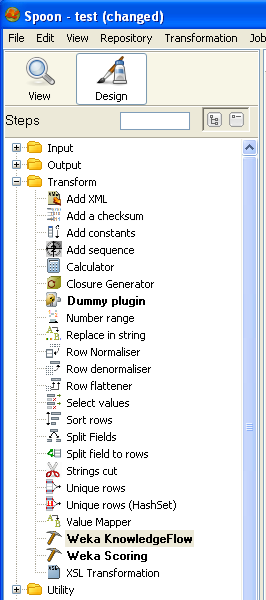
Once installed correctly, you will find the Kettle Knowledge Flow step in the "Transform" folder in the Spoon user interface.
4 Using the Knowledge Flow Plugin
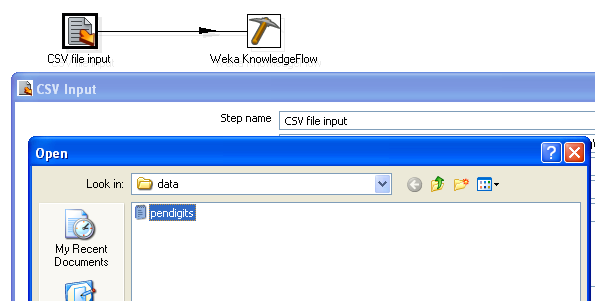
As a simple example, we will use the Knowledge Flow step to create and export a predictive model for the "pendigits.csv"data set (SampleDataAndDocs.zip). This data set is also used in the "Using the Weka Scoring Plugin"documentation.
4.1 Create a Simple Transformation
First construct a simple Kettle transformation that links a CSV input step to the Knowledge Flow step. Next configure the input step to load the "pendigits.csv" file. Make sure that the Delimiter text box contains a "," and then click "Get Fields" to make the CSV input step analyze a few lines of the file and determine the types of the fields. Also make sure that the "Lazy conversion" checkbox is unselected (see the "Tips and Tricks" section of Using the Weka Scoring Plugin for more information).
All the fields in the "pendigits.csv" file are integers. However, the problem is a discrete classification task and Weka will need the "class" field to be declared as a nominal attribute. In the CSV input step's configuration dialog, change the type of the "class" field from "Integer" to "String." 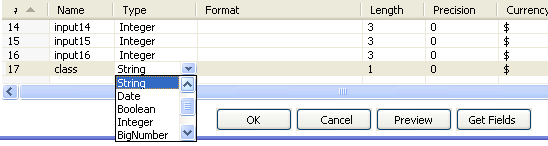
4.2 Configuring the Knowledge Flow Kettle Step
The Knowledge Flow step's configuration dialog is made up of three tabs (although only two are visible initially when the dialog is first opened). The first tab, "KnowledgeFlow file," enables existing Knowledge Flow flow definition files to be loaded or imported from disk. It also allows you to configure how the incoming data from the transformation is connected to the Knowledge Flow process and how to deal with the output.
If a flow definition is loaded, then the definition file will be loaded (sourced) from the disk every time that the transformation is executed. If, on the other hand, the the flow definition file is imported, it will be stored in either the transformation's XML configuration file (.ktr file) or the repository (if one is being used).
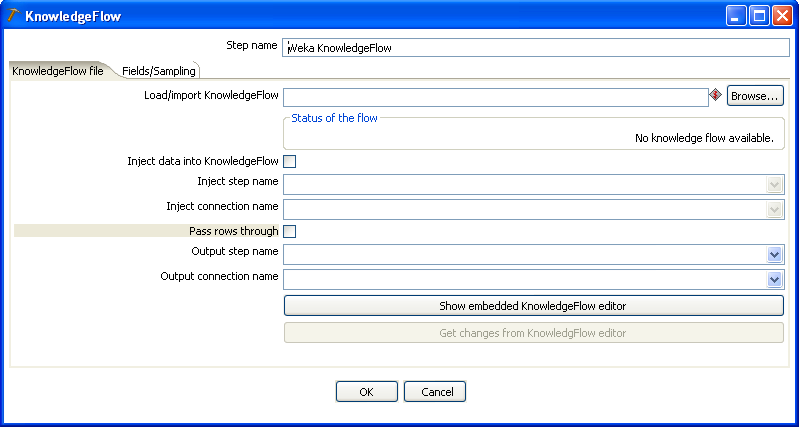
A third option is to design a new Knowledge Flow process from scratch using the embedded Knowledge Flow editor. In this case the new flow definition will be stored in the .ktr file/repository. This is the approach we will take for the purposes of demonstration.
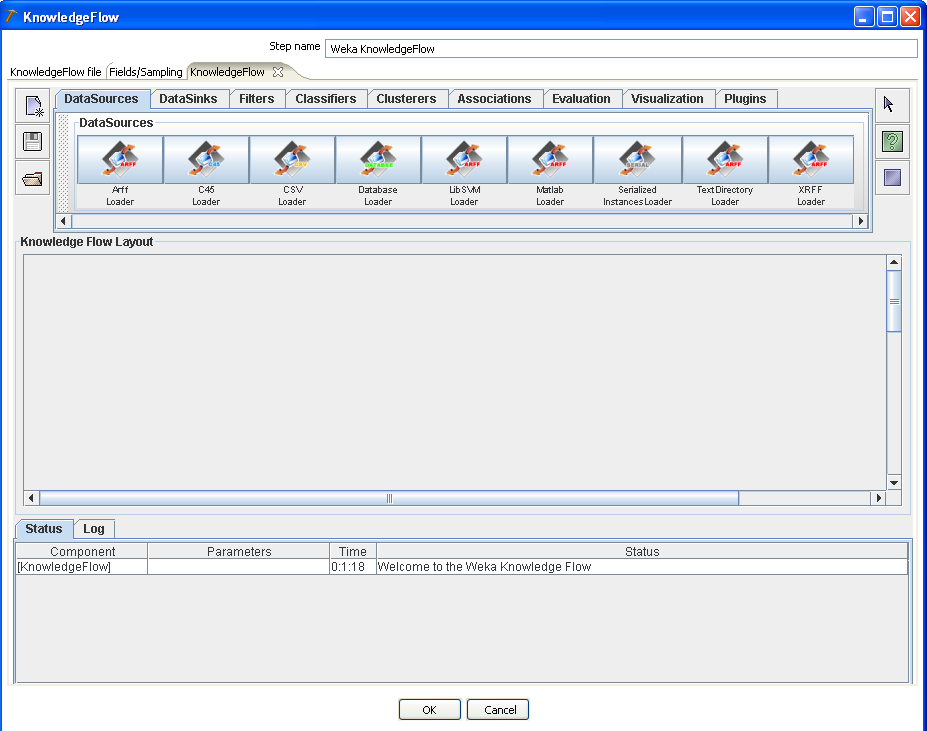
4.2.1 Creating a Knowledge Flow Process Using the Embedded Editor
Clicking the "Show embedded KnowledgeFlow editor" button will cause a new "KnowledgeFlow" tab to appear on the dialog.
Note
You may need to enlarge the size of the Knowledge Flow step's dialog in order to fully see the embedded editor.
To begin with, we will need an entry point into the data mining process for data from the Kettle transformation. Select the "Plugins" tab of the embedded editor and place a "KettleInject" step onto the layout canvas. If there is no "Plugins" tab visible, or there is no "KettleInject" step available from the "Plugins" tab, you will need to review the installation process described earlier. 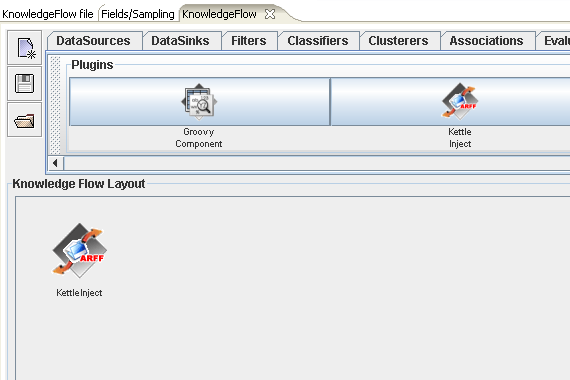
Next, connect a "TrainingSetMaker" step to the "KettleInject" step by right clicking over "KettleInject" and selecting "dataSet" from the list of connections. 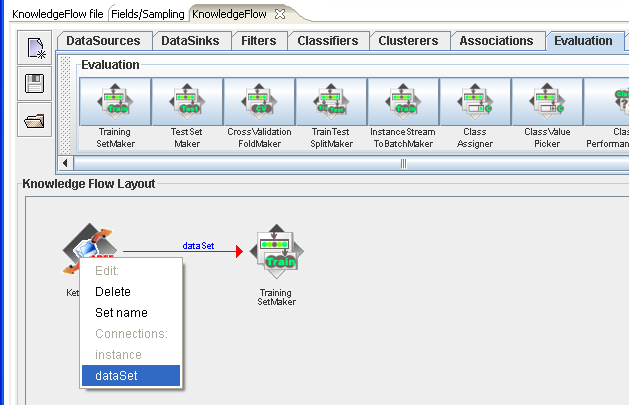
Now add a logistic regression classifier to the flow and connect it by right clicking over "TrainingSetMaker" and selecting "trainingSet" from the list of connections. 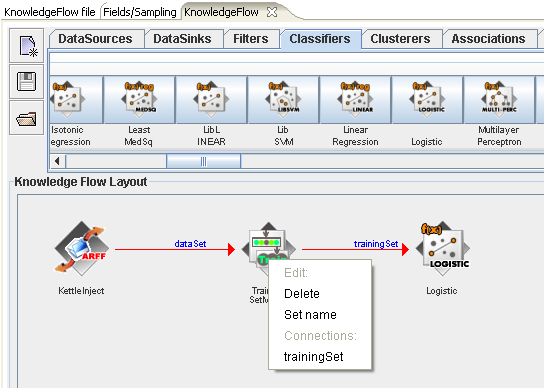
Next, connect a "SerializedModelSaver" step and connect it by right clicking over "Logistic" and selecting "batchClassifier" from the list of connections. 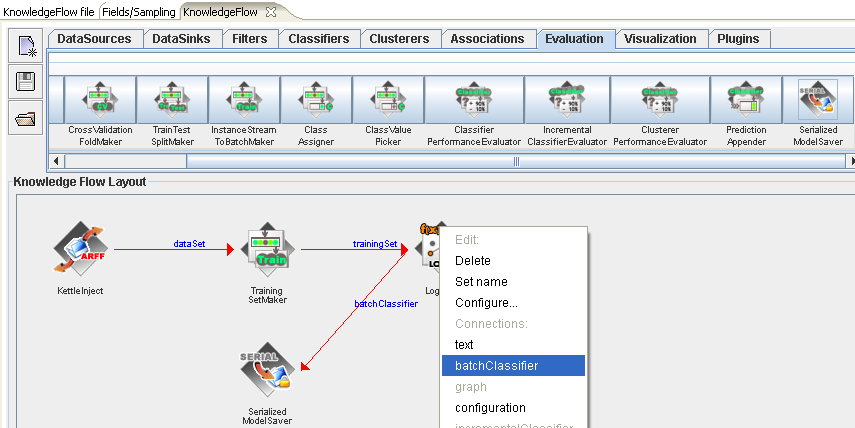
Now configure the "SerializedModelSaver" in order to specify a location to save the trained model to. Either double click the icon or right click over it and select "Configure..." from the pop-up menu. If you are using Weka version 3.7.x, there is support for environment variables in the Knowledge Flow and Kettle's internal environment variables are available. In the screenshot below, we are saving the trained classifier to ${Internal.Transformation.Filename.Directory} - this is the directory that the Kettle transformation has been saved to (Note: this only makes sense if a repository is not being used). You can always specify an absolute path to a directory on your file system, and, in fact, this is necessary if you are using Weka version 3.6.x. 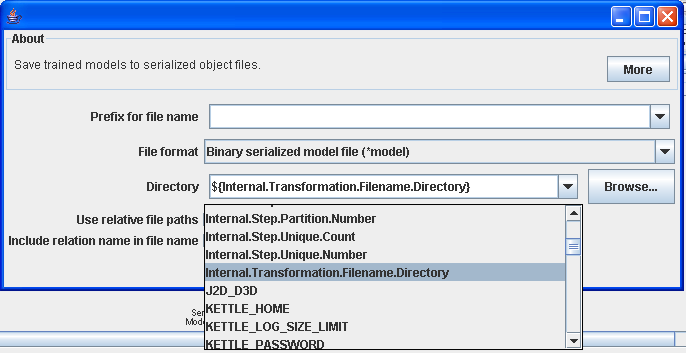
Finally, add a "TextViewer" step to the layout and connect it to the "Logistic" step by right clicking over "Logistic" and selecting "text" from the list of connections. The "TextViewer" step will receive the textual description of the model structure learned by the logistic regression.
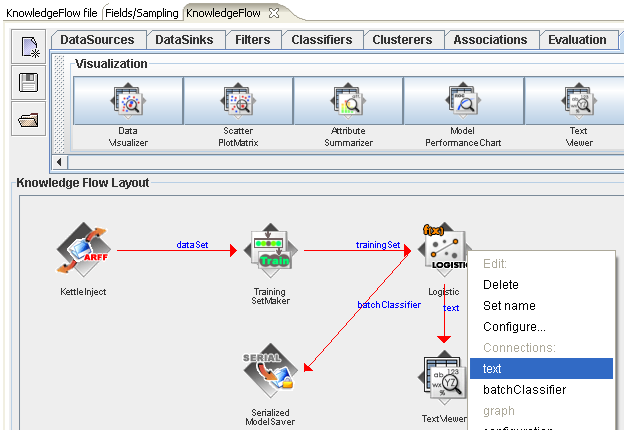
4.2.2 Linking the Knowledge Flow Data Mining Process to the Kettle Transformation
Now we can return to the "KnowledgeFlow file" tab in the Knowledge Flow Kettle step's configuration dialog and establish how data is to be passed in to and out of the Knowledge Flow process that we've just designed. First click the "Get changes from KnowledgeFlow editor" button. This will extract the flow from the editor and populate the drop-down boxes with applicable step and connection names. To specify that incoming data should be passed in to the Knowledge Flow process, select the "Inject data into KnowledgeFlow" checkbox and choose "KettleInject" in the "Inject step name" field. The "Inject connection name" field will be automatically filled in for you with the value "dataSet." 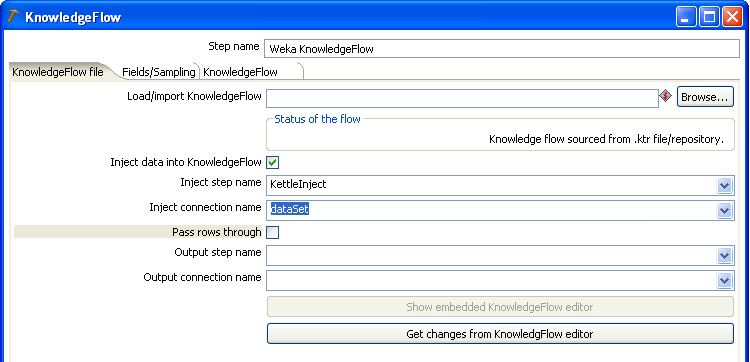
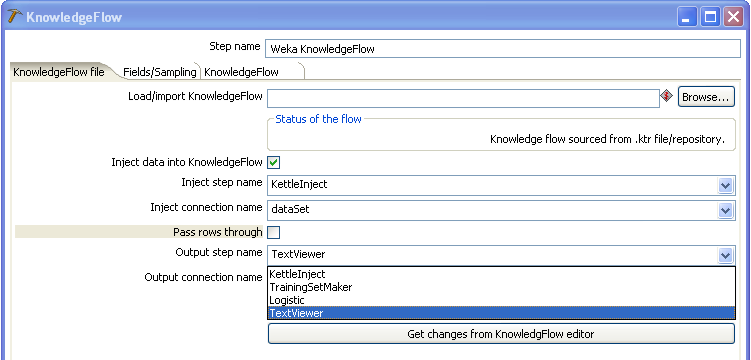
The choices for output include either passing the incoming data rows through to downstream Kettle steps or to pick up output from the Knowledge Flow process and pass that on instead. In this example we will do the latter by picking up output from the "TextViewer" step in the Knowledge Flow process. Note that the "SerializedModelSaver" step writes to disk and does not produce output that we can pass on inside of a Kettle transformation. Select "TextViewer" in the "Output step name" field and "text" in the "Output connection name" field. Make sure to leave "Pass rows through" unchecked.
4.2.3 Choosing Fields and Configuring Sampling
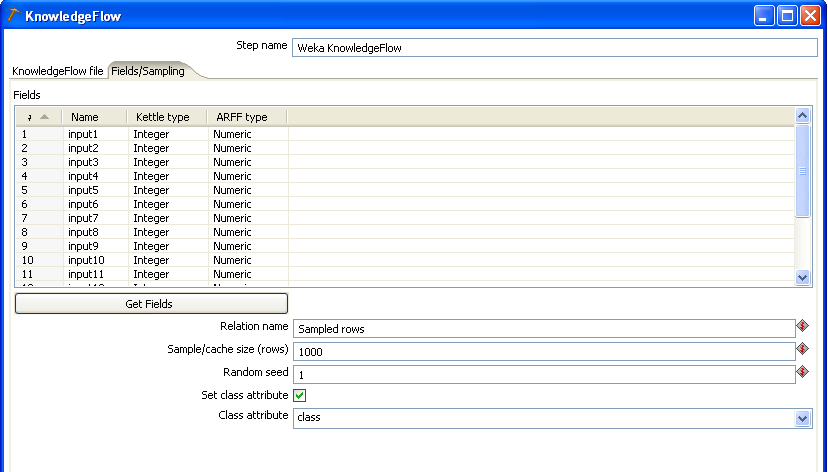
The second tab of the Knowledge Flow Kettle plugin's configuration dialog allows you to specify which of the incoming data fields are to be passed in to the data mining process and whether or not to down sample the incoming data stream.
Note
This tab is only applicable when data is being injected into the Knowledge Flow process.
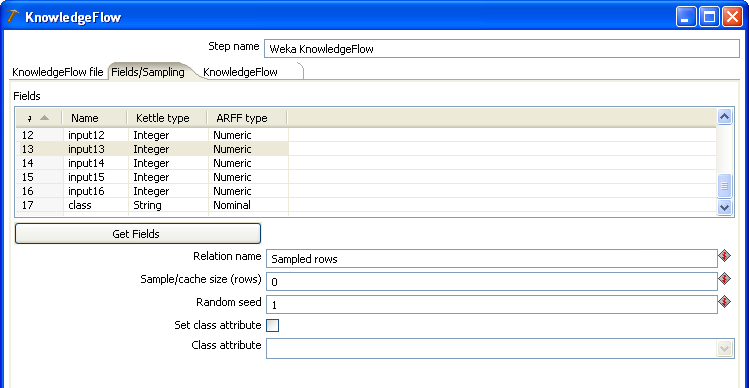
The table in the upper portion of the tab shows the incoming Kettle fields, their type and corresponding Weka type. The table allows you to delete any fields that you don't wan't to become input to the data mining process. Clicking on the "Get fields" button will reset the table with all incoming fields.
Directly below the "Get fields" button is a text field that allows you to enter a relation name for the Weka data set that will be constructed from the incoming Kettle data. This is set to "Sampled rows" by default, but you may enter any descriptive string you like here.
The next two text fields relate to sampling the incoming Kettle data. The Knowledge Flow Kettle step has built in Reservoir sampling (similar to that of the separate Reservoir Sampling plugin step). In batch training mode (incremental training is discussed in the "Advanced Features" section below) the "Sample/cache size (rows)" text field allows you to specify how many incoming Kettle rows should be randomly sampled and passed on to the Knowledge Flow data mining process. Reservoir sampling ensures that each row has an equal probability of ending up in the sample (uniform sampling). The "Random seed" text field provides a seed value for the random sampling process - changing this will result in a different random sample of the data. Entering a 0 (zero) in the "Sample/cache size" field tells the step that all the incoming data should be passed on to the data mining process (i.e. no sampling is to be performed). For the purposes of this example, make sure that you enter a zero in this field or change the value to something more than the default 100 rows.
The "Set class attribute" allows you to indicate that a class or target attribute is to be set on the data set created for the data mining process. Select this checkbox and then select the "class" field from the "Class attribute" drop-down box. 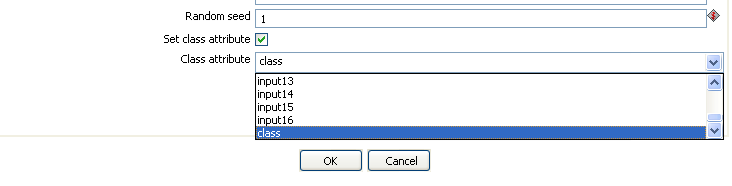
4.3 Running the Transformation
Before running the transformation, add a "Text file output" step in order to save the textual description of the logistic regression model. Note that instead of saving this model output, we could just as easily have it placed in a report by using this transformation as part of an action sequence running on the Pentaho BI server.
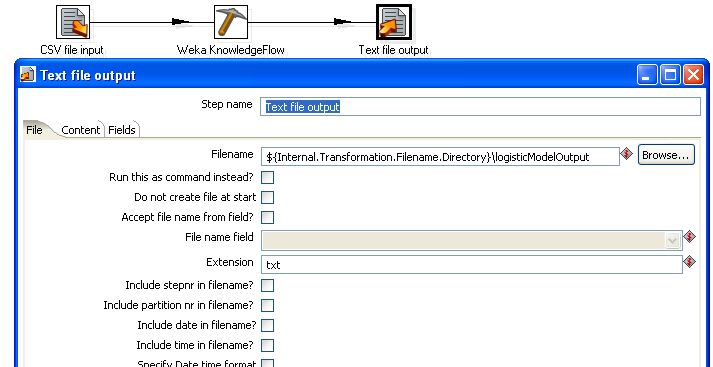
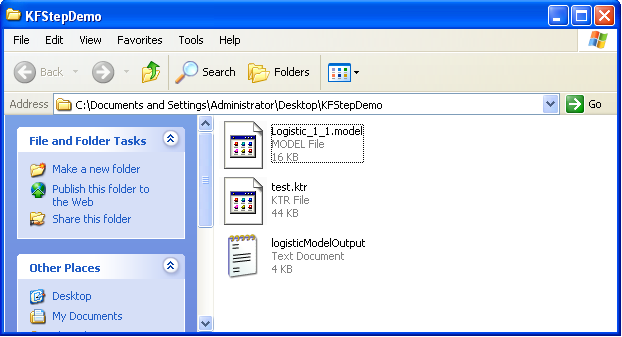
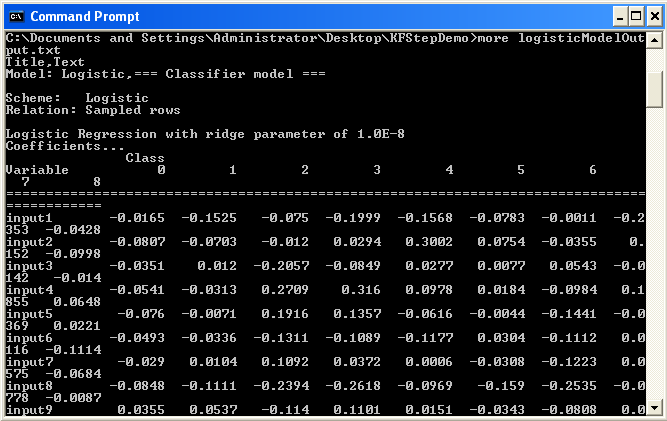
Now you can save the transformation and run it. Depending on the speed of your computer, the Knowledge Flow process may take up to a minute or so to train the logistic model. We can find the binary serialized model and textual model description in the same directory that the .ktr transformation file was saved to.
5 Advanced Features
Some learning algorithms in Weka are capable of being trained incrementally. Therefore, these classifiers are can hande a data stream and thus do not require down-sampling (as batch learning processes might do for large data sets). The Weka Knowledge Flow Kettle plugin can handle this situation as the following example shows.
In the screenshot below, we have created a KnowledgeFlow process similar to the one used earlier, however, this time we are using an incremental classifier (NaiveBayesUpdateable) and the link between the KettleInject step and the classifier is an "instance" connection. As before, we are saving the learned model out to a file on the file system. In this case, the saving of the model will occur after the last row of data in the stream has been processed. Similarly, the textual description of the model (collected by the TextViewer step) will be generated at the end of the data stream. 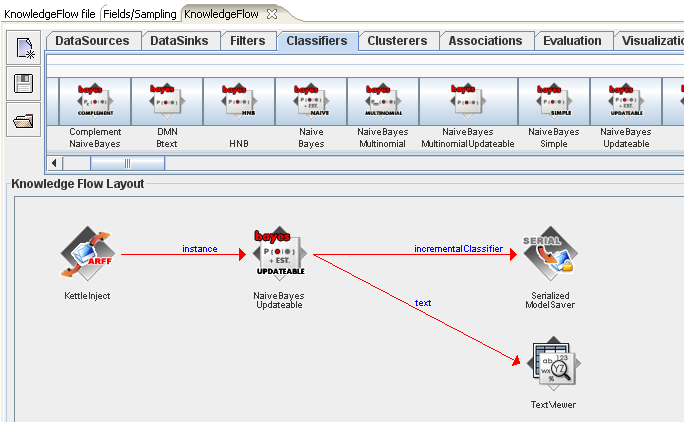
The configuration in the Knowledge Flow Kettle step's "KnowledgeFlow file" tab is also similar to before - the only change this time is to specify that data is to be injected into the Knowledge Flow process using an "instance" connection type. 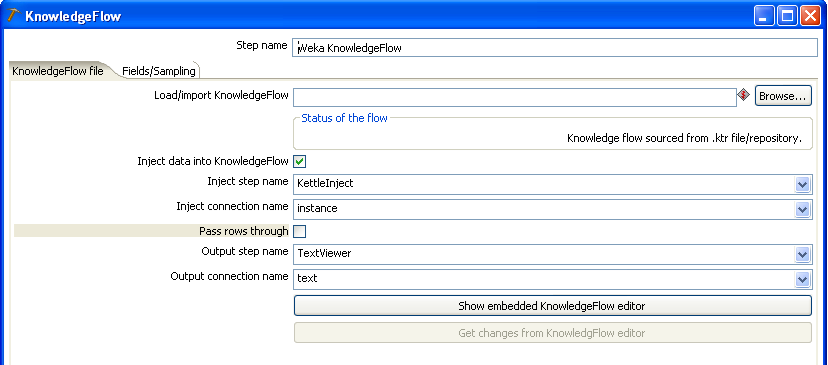
The settings in the "Fields/Sampling" tab is also similar to before. However, this time the number in the "Sample/cache size" field has a different meaning. In the case of handling a data stream, this number represents how many rows will be cached in order to determine the set of legal values for discrete (nominal)-valued fields. Weka's internal data format requires that discrete valued attributes have all their legal values declared apriori. So, in the screenshot below, the figure of 1000 indicates that the first 1000 data rows will be cached and analyzed to determine the values for all incoming "String" fields. If your data does not contain any discrete fields (including the target too), then this value may be safely set to 0. If your data does include discrete fields, and, during the course of execution, values occur that were not seen in the set of cached rows, then they will be set to missing values before being passed into the Knowledge Flow process. So, to achieve best results, it is important to set the cache size appropriately. Note: all cached rows will be passed to the Knowledge Flow process once the cache size is exceeded. The "Random seed" field has no affect in the case of incremental stream processing.